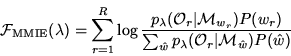T. Hain, P.C. Woodland, G. Evermann & D. Povey
Cambridge University Engineering
Department
Trumpington Street, Cambridge, CB2 1PZ, UK
email: {th223,
pcw,
ge204,
dp10006}@eng.cam.ac.uk
This paper describes the Cambridge University HTK (CU-HTK) system developed for the NIST March 2000 evaluation of English conversational telephone speech transcription (Hub5E). A range of new features have been added to the HTK system used in the 1998 Hub5 evaluation, and the changes taken together have resulted in an 11% relative decrease in word error rate on the 1998 evaluation test set. Major changes include the use of maximum mutual information estimation in training as well as conventional maximum likelihood estimation; the use of a full variance transform for adaptation; the inclusion of unigram pronunciation probabilities; and word-level posterior probability estimation using confusion networks for use in minimum word error rate decoding, confidence score estimation and system combination. On the March 2000 Hub5 evaluation set the CU-HTK system gave an overall word error rate of 25.4%, which was the best performance by a statistically significant margin. This paper describes the new system features and gives the results of each processing stage for both the 1998 and 2000 evaluation sets.
Major system changes include the use of HMMs trained using maximum mutual information estimation (MMIE) in addition to standard maximum likelihood estimation (MLE); the use of pronunciation probabilities; improved speaker/channel adaptation using a global full variance transform; soft-tying of states for the MLE based acoustic models; and the use of confusion networks for minimum word error rate decoding, confidence score estimation and system combination. All of these features made a significant contribution to the word error rate improvements of the complete system. In addition, several minor changes have been made and these include the use of additional training data and revised transcriptions; acoustic data weighting; and an increased vocabulary size.
The rest of the paper is arranged as follows. First an overview of the 1998 HTK system is given. This is followed by a description of the data sets used in the experiments and then by sections that discuss each of the major new features of the system. Finally the complete March 2000 evaluation system is described and the results of each stage of processing presented.
The system uses perceptual linear prediction cepstral coefficients
derived from a mel-scale filterbank (MF-PLP) [18]
covering the frequency range from 125Hz to 3.8kHz. A total of 13
coefficients, including ![]() , and their first and second order
derivatives were used. Cepstral mean subtraction and variance
normalisation are performed for each conversation side. Vocal tract
length normalisation (VTLN) was applied in both training and test.
, and their first and second order
derivatives were used. Cepstral mean subtraction and variance
normalisation are performed for each conversation side. Vocal tract
length normalisation (VTLN) was applied in both training and test.
The acoustic modelling used cross-word triphone and quinphone hidden
Markov models (HMMs) trained using conventional maximum likelihood
estimation. Decision tree state clustering [20] was used
to select a set of context-dependent equivalence classes. Mixture
Gaussian distributions for each tied state were then trained using
sentence-level Baum-Welch estimation and iterative mixture splitting
[20]. After gender independent (GI) models had been
trained, a final training iteration using gender-specific training
data and updating only the means and mixture weights was performed to
estimate gender dependent (GD) model sets. The triphone models were
phone position independent, while the quinphone models included
questions about word boundaries as well as ![]() phone context. The
HMMs were trained on 180 hours of Hub5 training data.
phone context. The
HMMs were trained on 180 hours of Hub5 training data.
The system used a 27k vocabulary that covered all words in the acoustic training data. The core of the pronunciation dictionary was based on the 1993 LIMSI WSJ lexicon, but used a large number of additions along with various changes. The system used N-gram word-level language models. These were constructed by training separate models for transcriptions of the Hub5 acoustic training data and for Broadcast News data and then merging the resultant language models to effectively interpolate the component N-grams. The word-level 4-grams used were smoothed with a class-based trigram model using automatically derived classes [12].
The decoding was performed in stages with successively more complex acoustic and language model being applied in later stages. Initial passes were used for test-data warp factor selection, gender determination and finding an initial word string for unsupervised mean and variance maximum likelihood linear regression (MLLR) adaptation [8,3]. Word-level lattices were then created using adapted triphone HMMs and a bigram model which were expanded to included the full 4-gram and class model probabilities. Iterative MLLR [17] was then applied using quinphone models and confidence scores estimated using an N-best homogeneity measure for both the triphone and quinphone output. The final stage combined these two transcriptions using the ROVER program [2]. The system gave a 39.5% word error rate on the September 1998 evaluation data.
Three different training sets were used during the course of development: the 18 hour Minitrain set defined by BBN which gives a fast turnaround; the full 265 hour training set (h5train00) for the the March 2000 system and a subset of h5train00 denoted h5train00sub. The sizes of the training sets are given in Table 1 together with the number of conversation sides that each includes. The h5train00sub set was chosen to include all the speakers from Swb1 in h5train00 as well as a subset of the available CHE sides.
| ||||||||||||||||||||
The development test sets used were the subset of the 1997 Hub5 evaluation set used in [6], eval97sub, containing 10 conversation sides of Switchboard-2 (Swb2) data and 10 of CHE; and the 1998 evaluation data set, eval98, containing 40 sides of Swb2 and 40 CHE sides (in total about 3 hours of data). Furthermore results are given for the March 2000 evaluation data set, eval00, which has 40 sides of Swb1 and 40 CHE sides.
| |||||||||||||||||||||||||||
Basic gender independent, cross-word triphone versions of the system, with no adaptation, were constructed for each training set size. Table 2 shows the number of clustered speech states and the number of Gaussians per state for each of these systems as well as word error rates on eval97sub. An initial 3.5-fold increase in the amount of training data results in a 4.6% absolute reduction in word error rate (WER). However some of this large gain can be attributed to the careful selection of the h5train00sub set to have a good coverage of the full training material. A further approximately 3-fold increase in the amount of training data only brings a further 1.6% absolute reduction in WER.
For ![]() training observation sequences
training observation sequences
![]() with corresponding transcriptions
with corresponding transcriptions ![]() , the
MMIE objective function is given by
, the
MMIE objective function is given by
| (2) |
Normally the denominator of (1) requires a full recognition pass to evaluate on each iteration of training. However as discussed in [16] this can be approximated by using a word lattice which is generated once to constrain the number of word sequences considered. This lattice-based framework can be used to generate the necessary statistics to apply the Extended-Baum Welch (EBW) algorithm [5,13,16] to iteratively update the model parameters. The statistics required for EBW can be gathered by performing for each training utterance a forward-backward pass on the lattice corresponding to the numerator of (1) (i.e. the correct transcription) and on the recognition lattice for the denominator of (1). The implementation we have used is rather different to the one in [16] and does a full forward-backward pass constrained by (a margin around) the phone boundary times that make up each lattice arc. Furthermore the smoothing constant in the EBW equations is computed on a per-Gaussian basis for fast convergence and a novel weight update formulation used. The computational methods that we have adopted for Hub5 MMIE training are discussed in detail in [19].
While MMIE is very effective at reducing training set error a key issue is generalisation to test data. It is very important that the confusable data generated during training (as found from the posterior distribution of state occupancy for the recognition lattice) is representative to ensure good generalisation. If the posterior distribution is broadened, then generalisation performance can be improved. For this work, two methods were investigated: the use of acoustic scaling and a weakened language model.
Normally the language model probability and the acoustic model likelihoods are combined by scaling the language model log probabilities. This situation leads to a very large dynamic range in the combined likelihoods and a very sharp posterior distribution in the denominator of (1). An alternative is to scale down the acoustic model log likelihoods and as shown in [19] this acoustic scaling aids generalisation performance. Furthermore, it is important to enhance the discrimination of the acoustic models without overly relying on the language model to resolve difficulties. Therefore as suggested in [15] a unigram language model was used during MMIE training which also improves generalisation performance [19].
Experiments reported in [19] show that MMIE is effective for a range of training set sizes and model types. Table 3 shows word error rates using triphone HMMs trained on h5train00. These experiments required the generation of numerator and denominator lattices for each of the 267,611 training segments. It was found that two iterations of MMIE re-estimation gave the best test-set performance [19]. Comparing the lines in Table 3 show that, without data weighting, the overall error rate reduction from MMIE training is 2.6% absolute on eval97sub and 2.7% absolute on eval98.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The table also shows the effect of giving a factor of three weighting to the CHE training data (The test set is balanced across Switchboard and Call Home data but the training set isn't and so data weighting attempts to partially correct this imbalance). This reduced the error rate for the MLE models by 0.5% to 0.7% absolute, but has a much smaller beneficial effect for MMIE trained models. This is probably because while MLE training gives equal weight to all training utterances, MMIE training effectively gives greater weight to those training set utterances with low sentence posterior probabilities for the correct utterance.
MMIE was also used to train quinphone HMMs. The gain from MMIE training for quinphone HMMs was 1.9% absolute on eval97sub from a quinphone MLE system using acoustic data weighting. As shown in [19] the gains from MLLR adaptation are as great for MMIE models as for MLE trained models. Hence the primary acoustic models used in the March 2000 CU-HTK evaluation system used gender-independent MMIE trained HMMs.
For the March 2000 system, a revised and somewhat simplified implementation of soft-tying was investigated. For a given model set a single Gaussian per state version was created. For each speech state in the single Gaussian system, the nearest two other states were found using a log-overlap distance metric [14], which calculates the distance between two Gaussians as the area of overlap of the two probability density functions. All of the mixture components from the two nearest states and the original state of the original mixture Gaussian HMM are then used in a mixture distribution for the state. Thus the complete soft-tied system has the same number of Gaussians as the original system and three times as many mixture weights per state. After this revised structure has been created all system parameters are re-estimated. This approach allows the construction of both soft-tied triphone and quinphone systems in a straightforward manner.
| ||||||||||||||||||||||||||||||||||||||||||||
There is a reduction in WER of 0.3% absolute for triphones and 0.5% for quinphones and a further 0.6% absolute from using GD models. So far, soft-tying has only been used with MLE training, although the technique could also be applied to MMIE trained models.
The dictionaries in the HTK system explicitly contain silence models as part of a pronunciation. Experiments with or without inclusion of silence into the probability estimates were conducted [7]. The most successful scheme used three separate dictionary entries for each real pronunciation which differed by the word-end silence type: a no silence version; adding a short pause preserving cross-word context; and a general silence model altering context. The unigram ``pronunciation'' probability is found separately for each of these entries and the distributions are smoothed with the overall silence distributions. Finally all dictionary probabilities are renormalised so that the pronunciation for each word which has the highest probability is set to one. During recognition the (log) pronunciation probabilities are scaled by the same factor as used for the language model.
Table 4 shows that the use of pronunciation probabilities gives a reduction in WER of 1.4-1.7% absolute on eval98. On other test sets improvements greater than 1% absolute have also been obtained and size of the gains is found to be fairly independent of the complexity of the underlying system.
The estimates of the word posterior probabilities encoded in the confusion networks can be used directly as confidence scores (which are essentially word-level posteriors), but they tend to be over-estimates of the true posteriors. This effect is due to the assumption that the word lattices represent the relevant part of the search space. While they contain the most-likely paths, a significant part of the ``tail'' of the overall posterior distribution is missing. To compensate for this a decision tree was trained to map the estimates to confidence scores.
The confusion networks with their associated word posterior estimates were also used in an improved system combination scheme. Previously the ROVER technique introduced in [2] had been used to combine the 1-best output of multiple systems. Confusion network combination (CNC) can be seen as a generalisation of ROVER to confusion networks, i.e. it uses the competing word hypotheses and their posteriors encoded in the confusion sets instead of only considering the most likely word hypothesised by each system.
A more detailed description of the use of word posterior probabilities and their application to the Hub5 task can be found in [1].
The use of the MSU Swb1 training transcriptions for language modelling purposes raised certain issues. First, the average sentence length was 11.3 words compared to 9.5 words on the LDC transcripts that we previously used. This has the effect that LMs trained on the MSU transcripts have a higher test-set perplexity which is mainly due to the reduced probability of the sentence-end symbol. Since it was not known if LDC-style or MSU-style training transcripts would be more appropriate, both sets of data were used along with the broadcast news data. Bigram, trigram and 4-gram LMs were trained on each data set (LDC Hub5, MSU Hub5, BN) and merged to form an effective 3-way interpolation. Furthermore, as described in [6] a class-based trigram model using 400 automatically generated word classes [12,9] was built to smooth the merged 4-gram language model by a further interpolation step to form the language model used in lattice rescoring.
Subsequent passes rescored these lattices and operated in two branches: a branch using GI MMIE trained models (branch ``a'') and a branch using GD, soft-tied, MLE models (branch ``b''). Stage P4a/P4b used triphone models with standard global MLLR, a FV transform, pronunciation probabilities and confusion network decoding. The output of the respective branches served as the adaptation supervision to stage P5a/P5b. These were as P4a/P4b but were based on quinphone acoustic models. Finally for the MMIE branch only, a pass with two MLLR transforms was run (P6a). The final system word output and confidence scores was found by using CNC with the confusion networks from P4a, P4b, P6a and P5b.
|
The use of quinphone models instead of triphone models gives a further gain of 0.9% for both branches. Whereas the second adaptation stage with two speech transforms for the quinphone MMIE models brings 0.5%, after obtaining CN output the difference is only 0.2%. The final result after 4-fold system combination is 35.0%. This is an 11% reduction in WER relative to the CU-HTK evaluation result obtained on the same data set in 1998 (39.5%).
Note that confusion network output consistently improves performance by about 1% absolute and that combination of the 4 outputs using confusion network combination (CNC) is 0.4% absolute better than using the ROVER approach. Then confidence scores based on confusion networks give an improved normalised cross entropy (NCE) of 0.225 compared to 0.145 from the 1998 CU-HTK evaluation system which used N-best homogeneity based confidence scores.
|
It was again found that there is a fairly consistent 1% absolute reduction in WER from confusion networks. A contrast (not shown in the table) showed that on P2 the use of MMIE models had given a 2.1% absolute reduction in WER over the corresponding MLE models. The combination P4a+P6a denotes a system where only MMIE trained models have been used for decoding which yields a result 0.9% absolute better than the corresponding MLE combination (P5b+P4b). However, the inclusion of the MLE system outputs gives a 0.2% WER absolute improvement. The final error rate from the system (25.4%) was lowest in the evaluation by a statistically significant margin.
|
The pure MLE system (MLE models in P2/P3 and MLE lattices) performs 2.1% absolute poorer than the MMIE system on P2. Comparing the performance of MLE models in P4b, they are 0.7% poorer than in the eval setup (MLE models with MMIE lattices and adaptation supervision) without confusion networks but only 0.3% poorer with confusion networks. An interesting result shows that although the pure MLE branch is poorer than the mixed MMIE/MLE system it is still able to contribute to the 4-way combination by the same amount. Furthermore while the overall performance of the system is significantly enhanced by the use of MMIE models, the complete pure MLE system achieves a 36.8% WER on eval98.