Postscript Version Proc. RIAO 2000, Content-Based Multimedia Information Access, Vol. 2, pp. 1163-1177 (Paris,France, April 2000)
S.E. Johnson ¹ P. Jourlin ², K. Spärck Jones ² & P.C. Woodland ¹
| ¹ Cambridge University Engineering Department, | ² Cambridge University Computer Laboratory, |
| Trumpington Street, | Pembroke Street, |
| Cambridge, CB2 1PZ, UK. | Cambridge, CB2 3QG, UK. |
| { sej28, pcw}@eng.cam.ac.uk | { pj207, ksj}@cl.cam.ac.uk |
Results are presented using the 1999 TREC-8 Spoken Document Retrieval data for the task where no story boundaries are known. Experiments investigating the effectiveness of all aspects of the system are described and the relative benefits of automatically eliminating commercials, enforcing broadcast structure during retrieval, using relevance feedback, changing retrieval parameters and merging during post-processing are shown. An Average Precision of 46.5%, when duplicates are scored as irrelevant is shown to be achievable using this system.
With the ever increasing amount of information being stored in audio and video formats, it is necessary to develop efficient methods for accurately extracting relevant information from these media with little or no manual intervention. This is particularly important for the case of broadcast news since the density of important up-to-date information is generally high, but topic changes occur frequently and information on a given event will be scattered throughout the broadcasts.
Initially work done in Spoken Document Retrieval (SDR) focused on the automatic transcription of American broadcast news audio into manually pre-defined ``stories'', which were then run through a text-based retrieval engine [Garofolo et al., 1998, Garofolo et al., 1999]. However, manually-generating story boundaries is a time consuming task and is not feasible for large, constantly updated collections.
Some recent work has therefore focused on retrieving information automatically when no manual labels for story boundaries exist. There are two main techniques used for this type of task. The first involves creating quasi-stories by using a simple windowing function across automatically generated transcriptions and then running some window recombination after retrieval (e.g. [Abberley et al., 2000, Dharanipragada and Roukos, 1997, Dharanipragada et al., 1999, Robinson et al., 1999]). The second involves attempting to find structure within the broadcast automatically, for example with story segmentation, or detection of commercials. This generally involves generating a transcription and performing the segmentation using text-based methods (e.g. [van Mulbregt et al., 1999]), but it is also possible to use additional audio or video cues (e.g. [Hauptmann and Witbrock, 1998]). This paper describes experiments on a system which uses both ideas, exploiting properties of the audio to impose some structure on complete broadcasts, whilst using windowing techniques to find relevant passages during retrieval.
Section 2 describes the framework for the experiments reported in this paper including the data set used and the method of performance evaluation. Section 3 describes a method for automatically detecting and eliminating commercials using the audio data directly, whilst the overall recognition, indexing and retrieval system is described in section 4. More details about the experimental procedure and a discussion of the scoring measures are given in section 5. Experimental results showing the effect of commercial removal, enforcing structure within the broadcasts and improving the retrieval and post-processing are given in section 6 and finally conclusions are offered in section 7.
Participants had to automatically produce show:time stamps for each query for the portions of audio thought to be relevant to that query. These were then mapped to the appropriate story-ID and all but the first occurrence of each story was labelled as irrelevant. Any non-story audio, such as commercials or jingles was also scored as irrelevant before the standard IR measures of precision (proportion of retrieved documents that are relevant) and recall (proportion of relevant documents that are retrieved) were calculated. The overall performance measures reported in this paper is the Average Precision (averaged over precision values computed after each relevant document is retrieved) and R-precision (precision when the number of documents retrieved equals the number of relevant documents) averaged over all the queries. [1 of the 50 queries was adjudged to have no relevant documents within the TREC-8 corpus and therefore was not used in the calculation of AveP and R-precision.]
The data used for the evaluation was the February 1998 to June 1998 subset of the audio from the TDT-2 corpus. It consisted of 244 hours of Cable News Network (CNN) broadcasts, 102 hours from Voice of America (VOA), 93 hours from Public Radio International (PRI) and 62 hours from the American Broadcasting Company (ABC). All recognition had to be performed on-line, namely not using any material broadcast after the date of the show being processed, whilst retrieval was retrospective i.e. any data up until the end of the collection (June 30th 1998) could be used. The use of any manually-derived story boundary information was prohibited in both tasks.
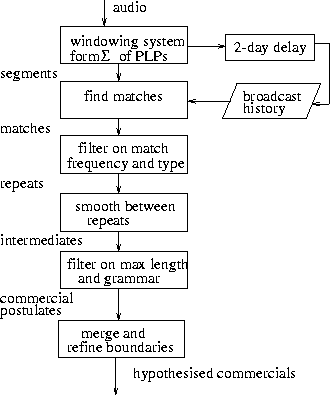
A system was built to automatically detect and remove commercials within the framework of the TREC-8 SU task. The commercial detector was based on finding segments of repeated audio using a method for direct audio search [Johnson and Woodland, 2000] making the assumption that (usually) only commercials are repeated. [Tony Robinson initially suggested the idea that repeated audio could indicate the presence of commercials.] The detector used a windowing system to divide the audio into overlapping segments of 5 seconds long with a shift of 1 second between adjacent windows. Each window was characterised by the covariance matrix of the (wideband) PLP cepstral coefficients as used in the subsequent speech recognition process. The windows were compared to a library of windows stored from previous shows from the broadcaster (the broadcast history) [In theory all the data in the test collection could be used (in an unsupervised way) for the library, but this was not allowed within the TREC-8 SU evaluation framework, as recognition was an on-line task.] using a direct match based on the arithmetic harmonic sphericity distance [Bimbot and Mathan, 1993] between the windows.
Safeguards were introduced to reduce the probability of stories being wrongly discarded, either due to false matches or to the story itself being rebroadcast by playing the same audio track during different news bulletins. These included forcing the match to occur a minimum number of times and in more than one preceding show and introducing a delay between the current show and the broadcast history.
Smoothing was then carried out to relabel sections of audio between matches as commercials, conditional on the resulting commercial being less than a maximum allowable length and, for the case of the CNN shows, fitting within a show grammar. Finally the boundaries of the postulated commercials were refined to take into account the courseness of the initial windows. This process is illustrated in Figure 1 and more details can be found in [Johnson et al., 2000].
Since the audio was eliminated at an early stage and could not be recovered later during processing, a very conservative system, C-1, which removed 8.4% of the audio, was used for the TREC-8 SDR evaluation. A contrast run, C-2, which removed 12.6% of the audio, was later made to see the effect of relaxing the tight constraints on the system. The breakdown of data removed using these systems compared to the manually-generated story labels is given in Table 1. Note that these ``reference'' labels are not an exact reflection of the story/commercial distinction, since a few commercials have been erroneously labelled as stories and some portions of actual news have not had story labels added and hence are wrongly scored as commercials; however they offer a reasonable indicator of the performance of the commercial detector.
| Broadcaster | Non-Stories | Stories | Total |
| C-1 | ABC | 12.8hrs=65.5% | 28s=0.02% | 12.8hrs=20.48% |
| CNN | 26.2hrs=35.7% | 2822s=0.46% | 27.0hrs=11.03% | |
| PRI | 1.9hrs=16.6% | 297s=0.10% | 2.0hrs= 2.16% | |
| VOA | 0.5hrs= 5.0% | 132s=0.04% | 0.5hrs= 0.49% | |
| ALL | 41.4hrs=36.3% | 0.9hrs=0.23% | 42.3hrs= 8.42% | |
| C-2 | ABC | 13.8hrs=70.6% | 107s=0.07% | 13.8hrs=22.12% |
| CNN | 43.3hrs=59.0% | 10640s=1.73% | 46.2hrs=18.91% | |
| PRI | 2.6hrs=22.4% | 416s=0.14% | 2.7hrs= 2.92% | |
| VOA | 0.6hrs= 6.0% | 208s=0.06% | 0.6hrs= 0.58% | |
| ALL | 60.2hrs=52.9% | 3.2hrs=0.81% | 63.4hrs=12.63% | |
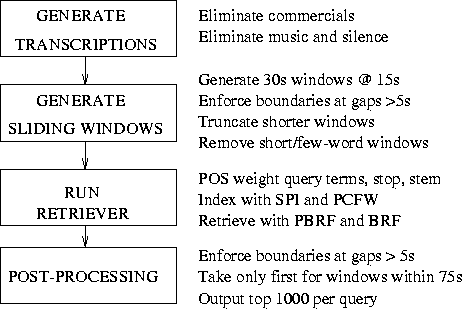
The main transcription system used a continuous mixture density, tied-state cross-word context-dependent HMM system based on the CUHTK-Entropic 1998 Hub4 10xRT system [Odell et al., 1999] and is described in more detail in [Johnson et al., 2000]. The data was coded into cepstral coefficients and cepstral mean normalisation was applied. A 2-pass system was implemented, the first pass used gender-independent, bandwidth-specific triphone models with a 60,000 word 4-gram language model. The output from this pass, denoted HTK-p1, gave a word error rate (WER) of 26.6% on the 10 hour scored subset of the TREC-8 SDR data.
A second pass used MLLR-adapted gender and bandwidth dependent triphone models with a 108,000 word trigram mixture language model to generate lattices from which a one-best output was made using a 4-gram model. This transcription, denoted HTK-p2, gave a WER of 20.5% on the scored subset.
The transcriptions were then divided into windows of length 30 seconds, with a 15 second shift between adjacent windows. Knowledge about the broadcast accumulated from the segmentation and commercial detection phases was incorporated into the windowing system by enforcing boundaries when a gap of over 5 seconds appeared in the transcriptions. Such gaps were thought to indicate the presence of either pure music (such as in a jingle), or commercials and hence offer a reasonable indicator of where a change in story might occur within the broadcast. Finally very short windows (less than a certain duration or number of words) were removed before retrieval.
Our Okapi-based retriever was used with traditional stopping and Porter stemming. Also included was a stemming exceptions list, and part-of-speech weighting for the query terms. Semantic poset indexing [Jourlin et al., 1999a] was used to capture some semantic information about geographical locations and unambiguous nouns, whilst parallel collection frequency weighting [Johnson et al., 2000] was used to obtain more robust estimates of the collection frequency (inverse document frequency) weights. Both traditional and parallel blind relevance feedback were used to add terms to the query during retrieval. A more detailed system description can be found in [Johnson et al., 2000].
Finally a post-processing stage was implemented to try to reduce the number of multiple hits (duplicates) from each story source. When two retrieved windows originated from within a certain time period in the same show, the one with the highest score was retained, whilst the other was discarded. However, the inferred structure of the broadcast was again used, by enforcing hard breaks at gaps of more than 5 seconds in the audio.
The scoring method for the TREC-8 SU evaluation mapped the show:time stamps given in the ranked list produced by the system, to a story-ID. All non-stories were scored as irrelevant and the first occurrence of each relevant story was scored as relevant. The difficulty arises when considering how to deal with duplicate hits from the same story. The method used in the evaluation scored all duplicates as irrelevant, irrespective of whether they represented a relevant story or not. Whilst this does reflect a real scenario to some degree, in that a user does not want to be presented with the same story more than once, it is a rather harsh scoring measure, and the reduction of duplicates seems to affect the score considerably more than an increase in the number of relevant documents found.
An alternative suggestion was to remove all duplicates before scoring, but this is also unsatisfactory since it encourages systems to over-generate story hits and produce many duplicates, which the user would not want to see. For example, suppose there were 50 relevant stories for a given query. Since the retriever returns the top 1000 matches, there would be no disincentive to produce 5 (or even 10) matches per story providing that there were not more than another 150 (or 50) non-relevant stories returned by the retriever.
In this paper, we use the official TREC-8 SU scoring procedure and quote the AveP and R-precision when all duplicates are scored as irrelevant. However, we supplement this figure by quoting the %retrieved (proportion of the entire set which has been retrieved) of relevant stories, (RS), non-relevant stories (NRS) and non-stories (NS), and give the number of duplicates. These latter measures are especially interesting, since they can be given at any stage of the system and unlike the Average and R-precision, are not influenced by how duplicates are scored.
The system described in section 4 gave an AveP of 41.47% on HTK-p2 and 41.50% on HTK-p1, in the TREC-8 SU evaluation, the R-precision being 41.98% and 41.63% respectively. [The AveP for our complete story-known system for the TREC-8 evaluation was 55.29% on HTK-p2 and 54.51% on HTK-p1.]
Two strategies for eliminating the commercials were compared. The first removed the sections of audio corresponding to the automatically labelled commercials before recognition, as in our original system. The second removed any windows returned by the retriever which occurred in a postulated commercial break, before the final post-processing stage, and thus could be applied to any retrieval system on any set of transcriptions.
The results before post-processing from applying no commercial elimination (-), the TREC-8 evaluation system (C-1) which removed 8.4% of the data, and the less conservative run (C-2) which removed 12.6% of the data are given in Table 2. The %retrieved for relevant stories (RS), non-relevant stories (NRS) and non-stories (NS) is given along with the number of duplicates (#Dup), before the final post-processing stage. The effect of removing the commercials before generating the transcriptions (BT) and after retrieving the windows (AR) is shown.
| BT | AR | RS | NRS | NS | #Dup |
| - | - | 94.7 | 39.3 | 25.6 | 734,897 |
| - | C-1 | 94.7 | 39.2 | 20.3 | 703,071 |
| - | C-2 | 94.4 | 39.0 | 17.4 | 690,069 |
| C-1 | - | 94.2 | 39.1 | 18.6 | 697,143 |
| C-1 | C-2 | 93.9 | 38.9 | 16.0 | 686,162 |
These results show that the %retrieved for
non-stories can be greatly
reduced by the automatic removal of commercials. When applying the
conservative C-1 system after retrieval, the %retrieved
for non-stories and the number
of duplicates can both be considerably reduced, without affecting
the %retrieved for relevant stories.
Further reductions in the retrieval of irrelevant and duplicate
information can be made by using the less conservative C-2
run or pre-filtering the audio, but at a slight cost to the
%retrieved for relevant stories.
The retrieval results after the post-processing
stage are given in Table 3.
| BT | AR | RS | NRS | NS | #Dup | AveP | R-P |
| - | - | 77.5 | 3.52 | 2.50 | 2550 | 41.00 | 40.96 |
| - | C-1 | 78.1 | 3.72 | 1.76 | 2658 | 41.22 | 41.34 |
| - | C-2 | 77.9 | 3.80 | 1.44 | 2720 | 41.13 | 41.50 |
| C-1 | - | 77.6 | 3.76 | 1.62 | 2667 | 41.50 | 41.63 |
| C-1 | C-2 | 77.6 | 3.84 | 1.32 | 2730 | 41.42 | 41.77 |
Filtering out windows thought to correspond to commercials after retrieval
can be performed using any retriever on any set of transcriptions.
For example, the results when applying the technique to the TREC-8
transcriptions from
LIMSI [Gauvain et al., 2000], which have a word error rate of 21.5%,
are shown in Table 4.
| AR | RS | NRS | NS | #Dup | AveP | R-P |
| - | 77.0 | 3.48 | 2.61 | 2610 | 40.19 | 41.12 |
| C-1 | 77.4 | 3.68 | 1.73 | 2710 | 40.75 | 41.79 |
| C-2 | 77.3 | 3.78 | 1.53 | 2701 | 40.49 | 41.94 |
These results show that the AveP can be increased by 1.4% relative on the transcriptions from LIMSI and 0.5% relative on the complete HTK-p1 transcriptions by filtering the windows returned by the retriever using the C-1 postulated commercial breaks. Both the R-precision and %retrieved for relevant stories also increase with a large drop in %retrieved for non-stories for this case. Using the C-2 postulated commercials gave a further increase in R-precision but led to a decrease in the relevant story %retrieved and AveP on both sets of transcriptions.
Despite the drop in the %retrieved for relevant stories before post-processing when the commercials are eliminated before recognition, the results in Table 3 show that better precision can be obtained when the commercial elimination is performed at the front-end of the system.
Implementing the C-1 commercial removal system before recognition thus produced a relative increase of 1.2% AveP and 1.6% R-P over the full HTK-p1 transcriptions whilst also reducing the amount of computational time required by 8.4%.
| Gap | RS | NRS | NS | #Dup | AveP | R-P |
| 3s | 78.2 | 3.66 | 1.66 | 3587 | 40.81 | 40.92 |
| 5s | 78.4 | 3.74 | 1.68 | 2707 | 41.47 | 41.98 |
| 10s | 78.3 | 3.76 | 1.67 | 2504 | 41.44 | 42.01 |
| | 78.3 | 3.77 | 1.67 | 2422 | 41.44 | 42.01 |
These results show that although many merges have been prevented by enforcing hard breaks at gaps of 5 seconds in the transcriptions, (leading to an increase in the number of duplicates), the overall results are practically unaffected. There is a very slight increase in relevant story %retrieved, due to distinct relevant stories which occur across a hard boundary no longer being incorrectly merged. However, some non-stories and non-relevant stories which would have been merged if no hard breaks had been enforced, now remain as separate entities. Since duplicates are scored as irrelevant, this practically counteracts the gain from not merging distinct relevant stories.
| Breaks | Post | RS | NRS | NS | #Dup | AveP | R-P |
| HB | B | 96.4 | 39.98 | 18.80 | 717829 | - | - |
| - | B | 96.0 | 39.39 | 27.42 | 752913 | - | - |
| HB | A | 78.4 | 3.74 | 1.68 | 2707 | 41.47 | 41.98 |
| - | A | 78.3 | 3.43 | 2.39 | 3801 | 41.71 | 40.07 |
These results show that using the structural information derived from segmentation and commercial elimination increases the %retrieved for relevant stories whilst also reducing the %retrieved for non-stories and number of duplicates both before and after post-processing. However, although the R-precision increases by 4.7% relative, the AveP decreases by 0.6% relative with a corresponding increase of 9% relative in non-relevant story %retrieved. It therefore appears that using 5 second gaps in the audio to restrict the initial window generation in the way described is not beneficial for retrieval (when measured by AveP, scoring duplicates as irrelevant) [It is not clear that increasing AveP to the detriment of other measures always increases performance from the point of view of real users, for example those concentrating only on high ranked documents.] so this was removed for subsequent experiments. [There was still a very small gain (0.1%) for the straight forward windowing when using the structural information to enforce hard breaks during post-processing.]
Although results on many sets of transcriptions for the TREC-7 SDR
data showed that SPI gave a small but consistent improvement in
AveP [Jourlin et al., 1999b], this did not appear to be the case when SPI was
included within our complete TREC-8 story-known evaluation
system [Johnson et al., 2000].
An experiment was therefore conducted to see the effect of removing
SPI from our story-unknown system.
| SPI | Post | RS | NRS | NS | #Dup | AveP | R-P |
| Y | B | 96.0 | 39.39 | 27.42 | 752913 | - | - |
| N | B | 95.8 | 37.52 | 24.92 | 698461 | - | - |
| Y | A | 78.3 | 3.43 | 2.39 | 3801 | 41.71 | 40.07 |
| N | A | 79.2 | 3.43 | 2.40 | 3764 | 43.42 | 43.35 |
The results, given in Table 7, show that including SPI does slightly increase relevant story %retrieved before post-processing. However, the non-relevant story and non-story %retrieved and the number of duplicates are also increased. After post-processing, the number of duplicates remains slightly higher for the SPI case, and the %retrieved for relevant stories drops. The decrease in AveP of 3.9% relative when including SPI is thought to be due to the inclusion of semantically related words adding significantly more non-relevant or non-stories than relevant stories during retrieval. [Note that there is a complicated interaction between the use of SPI and other techniques such as blind relevance feedback.] This unexpected result needs further investigation, but in the meantime SPI was removed for subsequent experiments.
| r | t | RS | NRS | NS | #Dup | AveP | R-P |
| 5 | 5 | 78.8 | 3.44 | 2.38 | 3719 | 42.69 | 43.48 |
| 10 | 5 | 79.2 | 3.43 | 2.40 | 3764 | 43.42 | 43.35 |
| 15 | 5 | 79.0 | 3.43 | 2.39 | 3765 | 42.83 | 43.59 |
| 20 | 5 | 78.9 | 3.43 | 2.40 | 3784 | 43.04 | 43.16 |
| 10 | 3 | 78.7 | 3.43 | 2.41 | 3773 | 42.40 | 42.71 |
| 10 | 5 | 79.2 | 3.43 | 2.40 | 3764 | 43.42 | 43.35 |
| 10 | 10 | 79.4 | 3.45 | 2.34 | 3742 | 44.28 | 44.23 |
| 10 | 12 | 79.3 | 3.45 | 2.34 | 3745 | 44.21 | 44.33 |
| 10 | 15 | 79.5 | 3.45 | 2.33 | 3733 | 44.20 | 44.50 |
| - | 0 | 78.4 | 3.45 | 2.37 | 3687 | 41.52 | 42.93 |
The results given in Table 8 show that including blind feedback within the system improved the AveP by 4.6% relative. The value of r chosen from experiments with a story-known system, seems to generalise well to the story-unknown case despite the different nature of the documents in both cases. However, AveP could be increased further by adding more terms to the query during the feedback process. [Although again the parameter set which gives best R-precision does not also give best AveP.] This increase in performance may be due to slightly sub-optimal values being used originally, or because of differences when moving from the story-known to story-unknown task, for example there are more ``documents'' and simple blind feedback now captures relatively more short-term dependencies than the parallel blind feedback which is not windowed.
| r | t | RS | NRS | NS | #Dup | AveP | R-P |
| 10 | 7 | 79.0 | 3.47 | 2.30 | 3635 | 43.44 | 45.05 |
| 15 | 7 | 80.1 | 3.46 | 2.30 | 3737 | 43.92 | 44.47 |
| 20 | 7 | 79.4 | 3.45 | 2.34 | 3742 | 44.28 | 44.23 |
| 25 | 7 | 79.8 | 3.45 | 2.32 | 3785 | 44.02 | 45.61 |
| 30 | 7 | 80.5 | 3.44 | 2.34 | 3799 | 43.29 | 44.98 |
| 20 | 5 | 79.1 | 3.43 | 2.38 | 3786 | 43.22 | 42.96 |
| 20 | 7 | 79.4 | 3.45 | 2.34 | 3742 | 44.28 | 44.23 |
| 20 | 10 | 80.6 | 3.47 | 2.26 | 3736 | 44.23 | 44.68 |
| - | 0 | 77.2 | 3.48 | 2.30 | 3611 | 39.01 | 40.40 |
``The constant b, ... modifies the effect of document length. If b=1 the assumption is that documents are long simply because they are repetitive, while if b=0 the assumption is that they are long because they are multitopic''
For the story-unknown case, no prior information about the document
lengths is available, so we assume that longer documents would
contain more topics, implying that b should be set to 0.
Increasing K means that more emphasis is placed on the term frequencies,
so a word that occurs many times in a document becomes relatively
more important.
| b | K | RS | NRS | NS | #Dup | AveP | R-P |
| 0.0 | 1.0 | 79.3 | 3.64 | 1.84 | 3271 | 45.50 | 47.04 |
| 0.25 | 1.0 | 80.3 | 3.50 | 2.18 | 3643 | 45.50 | 45.05 |
| 0.5 | 1.0 | 79.4 | 3.45 | 2.34 | 3742 | 44.28 | 44.23 |
| 1.0 | 1.0 | 78.1 | 3.31 | 2.78 | 3934 | 39.86 | 40.50 |
| 0.0 | 0.75 | 79.1 | 3.64 | 1.85 | 3244 | 45.05 | 46.05 |
| 0.0 | 1.0 | 79.3 | 3.64 | 1.84 | 3271 | 45.50 | 47.04 |
| 0.0 | 1.25 | 79.4 | 3.64 | 1.83 | 3261 | 45.84 | 46.91 |
| 0.0 | 1.5 | 79.6 | 3.64 | 1.82 | 3277 | 44.96 | 45.34 |
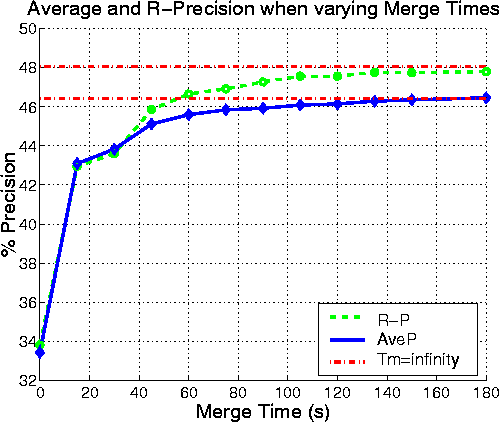
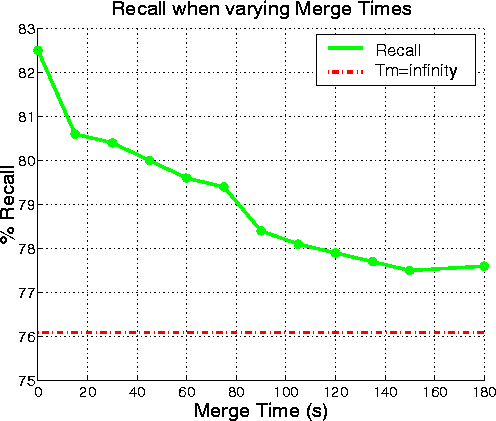
An experiment was conducted to find the effect on performance of varying Tm . The results are illustrated in Figure 3 and summarised in Table 11.
| Tm (s) | RS | NRS | NS | #Dup | AveP | R-P |
| 0 | 82.5 | 2.13 | 1.00 | 22188 | 33.43 | 33.82 |
| 15 | 80.6 | 3.30 | 1.63 | 7571 | 43.09 | 42.95 |
| 30 | 80.4 | 3.42 | 1.70 | 6030 | 43.83 | 43.60 |
| 45 | 80.0 | 3.52 | 1.78 | 4678 | 45.12 | 45.85 |
| 60 | 79.6 | 3.59 | 1.81 | 3896 | 45.59 | 46.65 |
| 75 | 79.4 | 3.64 | 1.83 | 3261 | 45.84 | 46.91 |
| 90 | 78.4 | 3.67 | 1.85 | 2877 | 45.92 | 47.26 |
| 120 | 77.9 | 3.71 | 1.88 | 2343 | 46.14 | 47.56 |
| 135 | 77.7 | 3.73 | 1.89 | 2184 | 46.28 | 47.76 |
| 150 | 77.5 | 3.73 | 1.91 | 2065 | 46.35 | 47.74 |
| 180 | 77.6 | 3.75 | 1.91 | 1874 | 46.45 | 47.79 |
| |
76.1 | 3.74 | 2.00 | 1677 | 46.41 | 48.05 |
The results show that both Average and R-Precision increase monotonically towards an asymptote as the merge time is increased suggesting that the ``best'' system would use a large merge time of around 3 minutes. [Using different merge times for different data sources will be also investigated in the future.] However, although merging dramatically decreases the number of duplicates, hence allowing the lower scoring relevant stories to gain a higher rank in retrieval (thus increasing precision), some distinct relevant stories are also being recombined (thus reducing relevant story %retrieved).
Although the precision values have reached an asymptote when Tm = 180s, relevant story %retrieved (i.e. recall) falls further when the merge time continues to be increased. Which value of Tm to use therefore depends on the relative importance of precision and recall to the user and in particular how they feel about seeing duplicates. It is felt that the Tm of our system (75s) offers a reasonable compromise between the rising precision and falling recall when merging is increased.
| Post | RS | NRS | NS | #Dup | # windows | |
| 0.1 | B | 96.5 | 44.20 | 30.41 | 871,428 | 1,448,864 |
| 1 | B | 95.4 | 33.05 | 21.80 | 574,486 | 1,003,679 |
| 5 | B | 89.8 | 10.38 | 5.58 | 127,084 | 259,030 |
| 7 | B | 86.4 | 6.30 | 3.46 | 73,592 | 154,450 |
| 10 | B | 82.1 | 3.22 | 1.66 | 38,499 | 80,196 |
| 12 | B | 76.1 | 2.14 | 1.11 | 25,873 | 53,969 |
| Post | RS | NRS | NS | #Dup | AveP | R-P | |
| 0.1 | A | 79.4 | 3.64 | 1.83 | 3261 | 45.84 | 46.91 |
| 1 | A | 79.4 | 3.64 | 1.83 | 3256 | 45.84 | 46.91 |
| 5 | A | 78.4 | 3.43 | 1.73 | 5238 | 45.82 | 46.91 |
| 7 | A | 77.2 | 3.17 | 1.66 | 6445 | 45.77 | 46.91 |
| 10 | A | 77.0 | 2.35 | 1.15 | 11919 | 45.78 | 46.91 |
| 12 | A | 72.7 | 1.78 | 0.86 | 12591 | 45.63 | 46.69 |
By increasing the low score threshold from 0.1 to 10, the final number of duplicates is increased, due to fewer intermediate windows being available for merging, and the %retrieved for relevant stories drops. However, the number of windows entering the post-processing stage can be reduced from 1,448,864 to 80,196 with a drop of less than 0.1% in AveP. For real systems, where speed of retrieval is important, the higher threshold should thus be used during post-processing.
We also hope to investigate whether the benefits of using parallel blind relevance feedback for document expansion on the TREC-8 story-known task [Johnson et al., 2000] can be translated into better performance for the story-unknown case.
A novel method of automatically detecting and eliminating commercials by directly searching the audio was used and was shown to increase performance for the TREC-8 story unknown task, whilst reducing the computational effort required by around 8% when implemented before recognition. Applying the automatically determined commercial boundaries as a filter after retrieval was also shown to improve performance on other sets of transcriptions.
A sophisticated large vocabulary speech recogniser was used to eliminate sections of audio corresponding to pure music and produce high quality transcriptions. Our final recognition system, using a 108,000 word vocabulary, ran in 13xRT [On a single processor of a dual processor Pentium III 550MHz running Linux.] and gave a WER of 20.5%, with the 60,000 word first-pass output giving 26.6% WER in 3xRT.
A windowing system was used to create quasi-documents on which the retrieval engine was run. A post-processing stage was then used to recombine windows thought to originate from the same story source by removing windows which were broadcast within a certain time of a higher scoring window. It was shown that incorporating the information about the structure of the broadcast gained from commercial elimination and segmentation, during the post-processing stage increased performance by a small amount, although no gain was found when using this information during window generation.
Experiments in retrieval showed that blind relevance feedback continued to be beneficial, but that semantic poset indexing, which had been found useful in earlier tests on other data [Jourlin et al., 1999a], was not helpful for this collection. Post-processing experiments showed precision could be increased at a cost to recall by performing more merging, whilst the speed of post-processing could be increased with little loss in precision, by using only the higher scoring windows from the retriever.
Combining the various techniques described in this paper has been shown to produce a system capable of giving an AveP of 46.5% on the TREC-8 story-unknown data set.