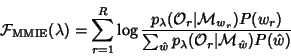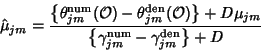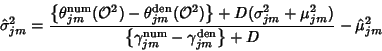P.C. Woodland & D. Povey
Cambridge University Engineering
Department
Trumpington Street, Cambridge, CB2 1PZ, UK
email: {pcw,
dp10006}@eng.cam.ac.uk
This paper describes a lattice-based framework for maximum mutual information estimation (MMIE) of HMM parameters which has been used to train HMM systems for conversational telephone speech transcription using up to 265 hours of training data. These experiments represent the largest-scale application of discriminative training techniques for speech recognition of which the authors are aware, and have led to significant reductions in word error rate for both triphone and quinphone HMMs compared to our best models trained using maximum likelihood estimation. The use of MMIE training was a key contributer to the performance of the CU-HTK March 2000 Hub5 evaluation system.
During MLE training, model parameters are adjusted to increase the likelihood of the word strings corresponding to the training utterances without taking account of the probability of other possible word strings. In contrast to MLE, discriminative training schemes, such as Maximum Mutual Information Estimation (MMIE) which is the focus of this paper, take account of possible competing word hypotheses and try and reduce the probability of incorrect hypotheses.
Discriminative schemes have been widely used in small vocabulary recognition tasks, where the relatively small number of competing hypotheses makes training viable. For large vocabulary tasks, especially on large datasets there are two main problems: generalisation to unseen data in order to increase test-set performance over MLE; and providing a viable computation framework to estimate confusable hypotheses and perform parameter estimation.
This paper is arranged as follows. First the details of the MMIE objective function are introduced. Then the lattice-based framework used for a compact encoding of alternative hypotheses is described along with the Extended Baum-Welch (EBW) algorithm for updating model parameters. Methods to enhance generalisation performance of MMIE trained systems are also discussed. Sets of experiments for evaluating the techniques on conversational telephone speech transcription are presented that show how MMIE training can be successfully applied over a range of training set sizes; the effect of methods to improve generalisation; and the interaction of MMIE with maximum-likelihood adaptation.
For ![]() training observation sequences
training observation sequences
![]() with corresponding transcriptions
with corresponding transcriptions ![]() , the
MMIE objective function is given by
, the
MMIE objective function is given by
| (2) |
It should be noted that optimisation of (1) requires the
maximisation of the numerator term
![]() , which is
identical to the MLE objective function, while simultaneously
minimising the denominator term
, which is
identical to the MLE objective function, while simultaneously
minimising the denominator term
![]() .
.
The update equations for the mean of a particular dimension of
the Gaussian for
state ![]() , mixture component
, mixture component ![]() ,
, ![]() and the corresponding variance,
and the corresponding variance, ![]() (assuming diagonal covariance matrices) can be re-estimated by
(assuming diagonal covariance matrices) can be re-estimated by
It is important to have an appropriate value for ![]() in the update equations, (3) and
(4). If the value set
is too large then training is very slow (but stable) and if it is too
small the updates may not increase the objective function on each
iteration. A useful lower bound on
in the update equations, (3) and
(4). If the value set
is too large then training is very slow (but stable) and if it is too
small the updates may not increase the objective function on each
iteration. A useful lower bound on ![]() is the value which ensures that
all variances remain positive.
Using a single global value of
is the value which ensures that
all variances remain positive.
Using a single global value of ![]() can lead to
very slow convergence, and in [9] a
phone-specific value of
can lead to
very slow convergence, and in [9] a
phone-specific value of ![]() was used.
was used.
In preliminary experiments, it was found that the convergence speed
could be further improved if ![]() was set on a per-Gaussian level,
i.e. a Gaussian specific
was set on a per-Gaussian level,
i.e. a Gaussian specific ![]() was used. It was set at the maximum
of i) twice the value necessary to ensure positive variance updates
for all dimensions of the Gaussian; or ii) the denominator occupancy
was used. It was set at the maximum
of i) twice the value necessary to ensure positive variance updates
for all dimensions of the Gaussian; or ii) the denominator occupancy
![]() .
.
The mixture weight values were set using a novel approach described in [7]. The exact update rule for the mixture weights is not too important for the decision-tree tied-state mixture Gaussian HMMs used in the experiments reported here, since the Gaussian means and variances play a much larger role in discrimination.
In [8] it was shown that improved test-set performance could be obtained using a unigram LM during MMIE training, even though a bigram or trigram was used during recognition. The aim is to provide more focus on the discrimination provided by the acoustic model by loosening the language model constraints. In this way, more confusable data is generated which improves generalisation. An unigram LM for MMIE training is investigated in this paper.
When combining the likelihoods from an HMM-based acoustic model and
the LM it is usual to scale the LM log probability. This is necessary
because, primarily due to invalid modelling assumptions, the HMM
underestimates the probability of acoustic vector sequences. An
alternative to LM scaling is to multiply the acoustic model log
likelihood values by the inverse of the LM scale factor (acoustic
model scaling). While this produces the same effect as language model
scaling when considering only a single word sequence as for Viterbi
decoding, when likelihoods from different sequences are added, such as
in the forward-backward algorithm or for the denominator of
(1), the effects of LM and acoustic model scaling are
very different. If language model scaling is used, one particular
state-sequence tends to dominate the likelihood at any point in time
and hence dominates any sums using path likelihoods. However, if
acoustic scaling is used, there will be several paths that have fairly
similar likelihoods which make a non-negligible contribution to the
summations. Therefore acoustic model scaling tends to increase the
confusable data set in training by broadening the posterior
distribution of state occupation
![]() that is used in
the EBW update equations. This increase in confusable data also leads
to improved generalisation performance.
that is used in
the EBW update equations. This increase in confusable data also leads
to improved generalisation performance.
The first step is to generate word-level lattices, normally using an MLE-trained HMM system and a bigram LM appropriate for the training set. This step is normally performed just once and for the experiments in Section 6 the word lattices were generated in about 5x Real-Time (RT). All run times are measured on an Intel Pentium III running at 550MHz.
The second step is to generate phone-marked lattices which label each word lattice arc with a phone/model sequence and the Viterbi segmentation points. These are are found from the word lattices and a particular HMM set, which may be different to the one used to generate the original word-level lattices. In our implementation, these phone marked lattices also encode the LM probabilities used in MMIE training which again may be different to the LM used to generate the original word-level lattices. This stage typically took about 2xRT to generate triphone-marked lattices for the experiments in Section 6, although the speed of this process could be considerably increased.
Given the phone-marked lattices for the numerator and denominator of each training audio segment, the lattice search used here performs a full forward-backward pass at the state-level constrained by the lattice and the statistics needed for the EBW updates accumulated. Pruning is performed by using the phone-marked lattice segmentation points extended by a short-period in each direction (typically 50ms at both the start and end of each phone). The search was also optimised as far as possible by combining redundantly repeated models which occur in the phone-marked lattice. Typically after compaction, the method requires about 1xRT per iteration for the experiments in Section 6.
The experiments investigated the effect of different training set and HMM set sizes and types; the use of acoustic likelihood scaling and unigram LMs in training and any possible interactions between MMIE training and maximum likelihood linear regression-based adaptation.
Incoming speech is parameterised into cepstral coefficients and their first and second derivatives to form a 39 dimensional vector every 10ms. Cepstral mean and variance normalisation and vocal tract length normalisation is performed for each conversation side in both training and test.
The HMMs are constructed using decision-tree based state-clustering and both triphone and quinphone models can be used. All experiments here used gender independent HMM sets. The pronunciation dictionary used in the experiments discussed below was for either a 27k vocabulary (as used in [4]) or a 54k vocabulary and the core of this dictionary is based on the LIMSI 1993 WSJ lexicon. The system uses word-based N-gram LMs estimated from an interpolation of Hub5 acoustic training transcriptions and Broadcast News texts. In the experiments reported here, trigram LMs are used unless otherwise stated.
| |||||||||||||||||||||||
The Minitrain 12 Gaussian/state results given in Table 1 compare acoustic and language model scaling for several iterations of MMIE training on the eval97sub test set (a subset of the 1997 Hub5 evaluation). It can be seen that acoustic scaling helps avoid over-training and the best WER is after 2 iterations. The training set lattices regenerated after a single MMIE iteration gave a WER of 16.8% and a LWER of 3.2%, showing that the technique is very effective in reducing training set error. However, it was found that these regenerated lattices were no better to use in subsequent training iterations and so all further work used just the initially generated word lattices.
| |||||||||||||||||||||||
The advantage of MMIE training for the 12 Gaussian per state system is small and so the same system with 6 Gaussians/state was trained. The results in Table 2 and again show the best performance after two MMIE iterations. Furthermore the gain over the MLE system is 1.7% absolute if a bigram LM is used and 1.9% absolute if a unigram LM is used: the 6 Gaussian per state MMIE-trained HMM set now slightly outperforms the 12 Gaussian system. Furthermore it can be seen that using a weakened LM (unigram) improves performance a little.
| ||||||||||||||||||||
The results in Table 3 show that again the peak improvement comes after two iterations, but there is an even larger reduction in WER: 2.3% absolute on eval97sub and 1.9% absolute on eval98. The word error rate for the 1-best hypothesis from the original bigram word lattices measured on 10% of the training data was 27.4%. The MMIE models obtained after two iterations on the same portion of training data gave an error rate of 21.2%, so again MMIE provided a very sizeable reduction in training set error.
| |||||||||||||||||||||||
We also experimented with data-weighting with this setup during MMIE training. The rationale for this is that while the test data sets contain equal amounts of Switchboard and CHE data, the training set is not balanced. Therefore we gave a 3x higher weighting to CHE data during training. The results of these experiments on both the eval97sub and eval98 test sets are shown in Table 4. It can be seen that there is an improvement in WER of 2.6% absolute on eval97sub and 2.7% on eval98.
Data weighting gives a further small improvement, although interestingly, data weighting for MLE reduces the WER by 0.7% absolute on eval97sub. It might be concluded that the extra weight placed on poorly recognised data by MMIE training relative to MLE reduces the need for the data weighting technique.
The quinphone MMIE training used triphone-generated word lattices, but, since the phone-marked lattices were re-generated for the quinphone models, it was necessary to further prune the word-lattices. The results of MMIE trained quinphones on the eval97sub set are shown in Table 5. Note that these experiments, unlike all previous ones reported here, include pronunciation probabilities.
|
As with the MMIE training runs discussed above, the largest WER reduction (2.1% absolute) comes after two iterations of training. The reductions in error rate are similar to those seen for triphone models when CHE data weighting is used even though there was extra pruning required for the phone-marked lattices and there were rather more HMM parameters to estimate.
| ||||||||||||||
The results in Table 6 show that the MMIE models are 2.1% absolute better than the MLE models without MLLR, and 2.2% better with MLLR. In this case, MLLR seems to work just as well with MMIE trained models: a relatively small number of parameters are being estimated with MLLR and these global transforms keep the Gaussians in the same ``configuration'' as optimised by MMIE.