Open Domain Statistical Spoken Dialogue Systems
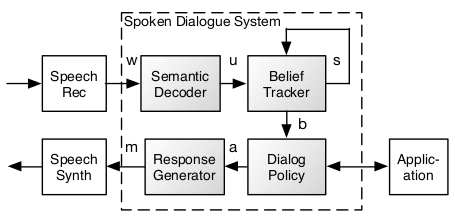
In a conventional SDS, all of the shaded components are rule-driven (Bratman 1988, Paek and Pieraccini 2008).
In a statistical SDS, however, the end-to-end process is modelled as a partially observable Markov decision process (POMDP)(Young 2006, Williams and Young 2007).
To avoid losing information by making hard decisions too early, w and u are replaced by probability distributions over all possible words and user acts, and the mapping from w to u is performed using a classifier trained on real data. The belief state b comprises the probability distribution over all possible states i.e. bi=p(si) and the policy a=π(b) is trained via interactions with real users to maximise a reward function using reinforcement learning. Finally, the selected action is converted to a response message m using a generative model trained on data. The replacement of best estimates for w, u and b by full probability distributions and the replacement of rules by optimised statistical models results in systems which are more robust to speech recognition errors and which can continue to improve on-line as more data is collected (Gasic et al. 2013, Young et al. 2014).
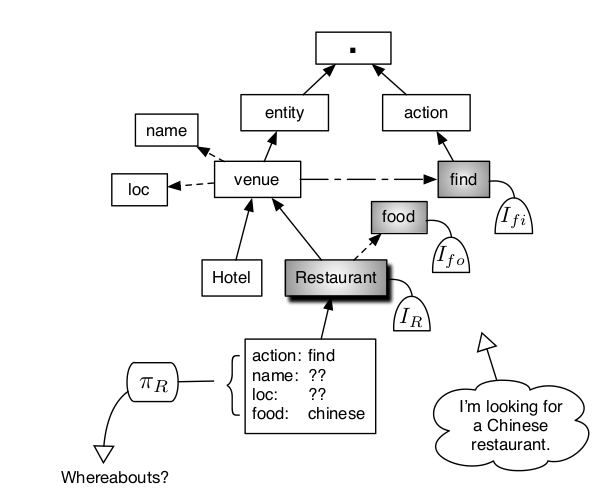
An open-domain spoken dialogue system is defined as one which can support a natural conversation about any topic within a wide coverage Knowledge Graph (KG). It is assumed that this graph contains not only ontological information about entities but also the operations that might be applied to those entities (e.g. find flight information, book a hotel room, buy an ebook, etc. ).
The figure above shows a fragment of a KG covering Hotels and Restaurants, both of which are specialisations of the venue class. When the user says "I am looking for a Chinese restaurant", the decoders attached to the Restaurant, food and find nodes are activated (as would other nodes in the graph such as chinese as a kind of language). Based on the recent history and the node activations, the topic tracker identifies Restaurant as the focus and activates its dialogue policy. The belief state for this node consists of probability distributions over the required action, name, location and food type. In this case, the policy selects the action request(loc) and the response ``Whereabouts?" is generated.
The inherit and adapt approach to on-line system training
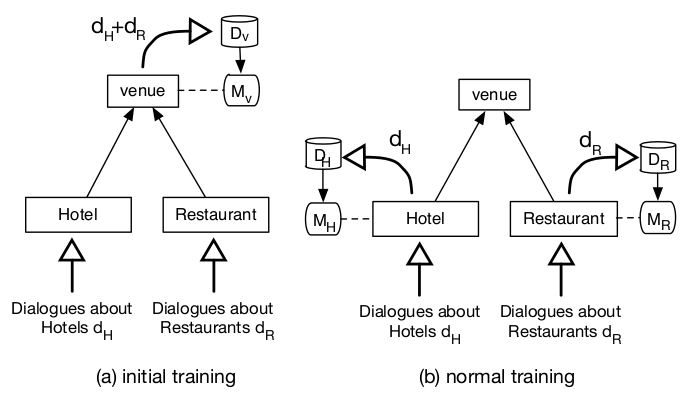
Initially, a small amount of corpus data is used to train the dialogue models Mv=(Iv,πv,Ov) required for input, decision policy and output for the venue class. As the system is used, data is accumulated and the venue class models are refined. At some point, there is sufficient data to train specific dialogue models for Restaurants and Hotels. At this point the data is split, and subsequent refinement takes place at the lower level.