
Contents:
Project Staff:
¹
Cambridge University Engineering Department
²
Cambridge University Computer Laboratory
³ Olivetti Research Laboratory
Interest in video-based communications and multimedia is growing
rapidly. Cambridge University, in collaboration with Olivetti Research
Laboratory (ORL), is developing the Medusa networked
multimedia system, which is now in regular use on a high speed
ATM network covering
ORL, the Computer Laboratory and
the Engineering Department's SVR Group. One of the most
popular Medusa services is video mail, and users are now amassing large
archives of stored video messages. However, unlike regular electronic
mail which is easily searched using conventional text retrieval methods,
video mail only has images and sound. The goal of this project is to
develop retrieval methods based on spotting keywords in the audio
soundtrack. The project has successfully integrated
speech recognition methods and
information retrieval technology
to yield a practical
audio and video retrieval system.
This project was supported by the UK DTI Grant IED4/1/5804 and
SERC Grant GR/H87629.
-> return to top
- To develop robust unrestricted keyword spotting algorithms for use
in audio and video document retrieval.
- To adapt existing text-based information retrieval techniques to work
effectively on voice and video data types.
- To develop and demonstrate a practical system providing video document
retrieval using voice.
-> return to top
The project is organised in 3 stages, each lasting one year and
culminating in a prototype demonstration system. The first stage
prototype was completed in September 1994 and successfully demonstrated
message retrieval from known speakers using a set of 35 predefined
keywords. The second stage, completed in September of 1995, extended
this to allow unknown speakers. In July 1996 the final stage
demonstrated open-keyword video document retrieval from arbitrary
speakers, as well as a video mail browser allowing random access to
video documents.
Finding interesting material in a large collection of documents is often
time consuming and inefficient. In automated text retrieval systems
statistical techniques are applied to a search query, seeking relevant
material present in the document archive. The retrieval system outputs
a list of potentially relevant documents for the user to inspect, ranked
by a score reflecting the match between the query and each individual
document.
Effective retrieval systems for electronic text archives have been
developed using this statistical approach, while similar methods are now
being used for Web search engines. But while text documents may be
readily indexed by their contents, determining the information content
of audio documents is considerably more difficult. documents. In the
absence of manually-generated transcriptions, spoken documents can be
retrieved only if their contents can be indexed using an automatic
speech recognition (ASR) system. Speech recognition is a non-trivial
process and presents several challenges in the retrieval domain.
-> return to top
Ideally, a speech recogniser would generate an exact transcription of
the document contents, regardless of speaking style, vocabulary, or
the acoustic environment. However, despite recent advances in ASR
technology, this ideal system is not yet practical.
State-of-the-art ASR systems can recognise vocabularies of many
thousands of words. However, out-of-vocabulary (OOV) words, such as many
proper nouns, cannot be recognised. This is a particular problem in
retrieval applications where users frequently wish to search using OOV
words including names of people, products, places or jargon.
The VMR system overcomes this problem using novel approach. The ASR
system generates a generalised sub-word or phone
lattice. Spoken words can be decomposed into a sequence of phone units
(of which there are about 45 in British English). Because speech
recognition is computationally expensive, the recognition phase is
performed in advance of retrieval. To search for a query word during
retrieval, the pre-computed lattices may be rapidly scanned (many times
faster than real-time) for phone strings corresponding to the query
word. As with all ASR systems, lattice word spotting is imperfect and is
prone to false alarms (hypotheses of a word when it is not
present), and misses (failures to hypothesise words which are
present). Experiments have shown that statistical methods
allow robust retrieval despite these search errors. ASR in the VMR
prototype is implemented using the Cambridge/Entropic
HTK toolkit with
speaker-independent hidden Markov models.
-> return to top
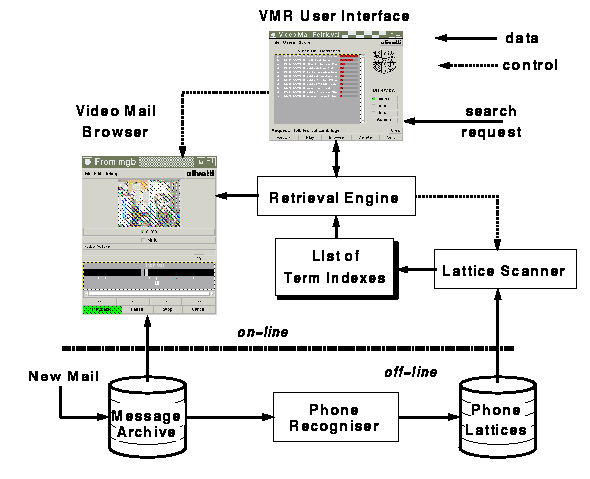
Figure 1. Block diagram of video mail retrieval system
Figure 1 shows an overview of the VMR system. New mail is passed to the
ASR which computes a phone lattice for the message. To search for
interesting messages, the user inputs words that indicate the
information need. A match score is then computed between the query and
each of the messages. The user is then presented with a ranked list of
the potentially most interesting messages.
The match score does not require all the query words to be present
in the message, but rather forms a query/message correlation
score. Individual words in each message are assigned a weight that
depends on the frequency of the word in the message, the number of
messages in which the word appears as well as the length of the
message. Thus, high scoring messages may actually have fewer matching
words than lower scoring ones. The retrieval system's user interface
presents the matching score graphically so that interesting messages may
be quickly identified.

Figure 2. Video mail retrieval GUI
Figure 2 shows the user interface displaying a ranked list of
messages --- the result of the query "folk festival cam-bridge." Prior to
a search, the message archive is shown ranked by date and time of
sending. The list can be narrowed to show only messages from selected
originators. When a query is entered the list is re-ranked by the
query/message match score. The bars to the the right of the messages
graphically indicate the relative score of each message.
-> return to top
While there are convenient methods for the graphical browsing
of text, eg scroll bars, ``page-forward'' commands, and word-search
functions, existing video and audio playback interfaces almost
universally adopt the ``tape recorder'' metaphor. To scan an entire
message, it must be auditioned from start to finish to ensure that no
parts are missed. Even if there is a ``fast forward'' button it is
generally a hit-or-miss operation to find a desired section in a lengthy
message. In contrast, the transcription of a minute-long message is
typically a paragraph of text, which may be scanned by eye in a matter
of seconds. Clearly there must be more economical ways to access and
review audio/video data.
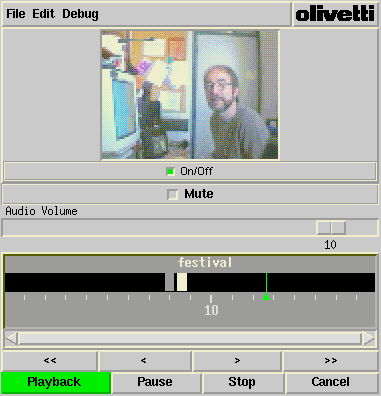
Figure 3. The video mail browser
The video browser shown in Figure 3 attempts to represent a dynamic
time-varying process (the video stream) by a static image that can be
taken in at a glance. A message is represented as horizontal timeline,
and keyword events are displayed graphically along it. Time runs from
left to right, and events are represented proportionally to when they
occur in the message; for example, events at the beginning appear on the
left side of the bar and short-duration events are short. In the
browser shown above, the timeline is the black bar and the scale
indicates time in seconds. During playback, or when pointed at with the
mouse, a keyword hit is highlighted and its name is displayed. (In the
figure, the keyword "FESTIVAL" has just been played.) The message may
be played starting at any time simply by clicking at the desired time in
the time bar; this lets the user selectively play regions of interest,
rather than the entire message.
-> return to top
The VMR project has demonstrated automatic retrieval of spoken documents
both experimentally and with a working prototype. Future work
will focus on combining phone lattice information with automatic
transcription and extending the retrieval techniques to handle larger and more
diverse message sets.
A new project on
Multimedia Document Retrieval
developping on from this work is now underway at Cambridge University.
-> return to top

- J.T. Foote, S.J. Young, G.J.F. Jones and K. Spärck Jones
Unconstrained keyword spotting using phone lattices with application
to spoken document retrieval
Computer Speech and Language, 11, 1997, pp. 207-224
- G.J.F. Jones, J.T. Foote, K. Spärck Jones and S.J. Young:
Video mail retrieval using voice: report on topic spotting
(Deliverable Report on VMR Task No. 6), Technical Report 430,
Computer Laboratory, University of Cambridge, 1997.
- S.J. Young, M.G. Brown, J.T. Foote, G.J.F. Jones and
K. Spärck Jones
Acoustic indexing for multimedia retrieval and browsing
Proc. ICASSP-97, Vol. 1, 1997, pp. 199-202
- G.J.F. Jones, J.T. Foote , K. Spärck Jones and S.J. Young:
Video mail retrieval using voice: report on collection of naturalistic
requests and relevance assessments
Technical Report 402, Computer Laboratory, University of Cambridge,
1996.
- M. G. Brown, J. T. Foote, G. J. F. Jones, K. Spärck Jones,
and S. J. Young.
Open-vocabulary speech indexing for voice and video mail retrieval.
Proc.
ACM Multimedia 96,
pp. 307-316 Boston, November 1996. ACM.
Best Paper Award
-
G. J. F. Jones, J. T. Foote, K. Spärck Jones, and
S. J. Young.
The Video Mail Retrieval project: Experiences in
retrieving spoken documents.
Intelligent Multimedia Information Retrieval, 1996.
Editor: M. T. Maybury, Menlo Park CA: AAAI Press, Cambridge MA: MIT Press, 1997
, pp. 191-214
-
G. J. F. Jones, J. T. Foote, K. Spärck Jones, and
S. J. Young.
Retrieving spoken documents by combining multiple index
sources.
Proc.
SIGIR 96,
Research and Development in Information Retrieval,pp 30-38
Zürich, August 1996. ACM.
Best Paper Award
-
G. J. F. Jones, J. T. Foote, K. Spärck Jones, and S. J. Young.
Robust talker-independent audio document retrieval.
Proc.
ICASSP 96, Vol. I, pp. 311-314, Atlanta, GA, May 1996.
- G. J. F. Jones, J. T. Foote, K. Spärck Jones, and
S. J. Young.
Video Mail Retrieval Using Voice: An Overview of the Stage
2 System.
Proc. of the Final Workshop on Multimedia Information Retrieval (MIRO
'95)
I. Ruthven, editor, Electronic Workshops in Computing,
Springer-Verlag, March 1996.
- K. Spärck Jones, G.J.F.Jones, J.T. Foote, S.J.Young
Experiments in Spoken Document Retrieval
Information Processing and Management, 32 (4), pp. 399-417, 1996
- K. Spärck Jones
Spoken Document Retrieval
Video of the Seminar: Computer Laboratory, University of Cambridge,
1995
-
M. G. Brown, J. T. Foote, G. J. F. Jones, K. Sparck Jones, and S. J. Young.
Automatic content-based retrieval of broadcast news.
Proc. ACM Multimedia 95
pp. 35-43, San Francisco, November 1995. ACM.
-
J. T. Foote, G. J. F. Jones, K. Spärck Jones, and S. J. Young.
Talker-independent keyword spotting for information retrieval.
Proc. Eurospeech 95, Vol. 3, pp. 2145-2148, Madrid,
September 1995. ESCA.
-
J. T. Foote, M. G. Brown, G. J. F. Jones, K. Spärck Jones, and S.J.
Young.
Video Mail Retrieval by voice: Towards intelligent retrieval
and browsing of multimedia documents.
Proc.
IMMI-1 ,
First International Workshop on Intelligence and Multimodality in
Multimedia Interfaces, Edinburgh, Scotland, July 1995.
-
K. Spärck Jones, J. T. Foote, G. J. F. Jones and S. J. Young.
Retrieving spoken documents: VMR Project experiments
Techincal Report 366, Computer Laboratory, University of Cambridge, 1995.
-
G. J. F. Jones, J. T. Foote, K. Spärck Jones, and S. J. Young.
Video Mail Retrieval: the effect of word spotting accuracy on
precision.
Proc. ICASSP 95, Vol. 1, pp. 309-312, Detroit, May 1995. IEEE.
-
K. Spärck Jones, J. T. Foote, G. J. F. Jones, and S. J. Young.
Spoken document retrieval --- a multimedia tool.
Fourth Annual Symposium on Document Analysis and Information
Retrieval,
pp. 1-11, University of Nevada, Las Vegas, January 1995.
-
M. G. Brown, J. T. Foote, G. J. F. Jones, K. Spärck Jones, and S. J.
Young.
Video Mail Retrieval using Voice: An overview of the
Cambridge/Olivetti retrieval system.
(see also
ORL Tech Report 94-8)
Proc.
ACM Multimedia 94
Workshop on Multimedia Database
Management Systems,
pp. 47-55, San Francisco, CA, October 1994.
-
G. J. F. Jones, J. T. Foote, K. Spärck Jones, and S. J. Young.
Video Mail Retrieval using Voice :
Report on keyword definition and data collection.
Technical Report 335, Computer Laboratory, University of Cambridge,
May 1994.
-> return to top
sej28@eng.cam.ac.uk
Mon Nov 10 1997