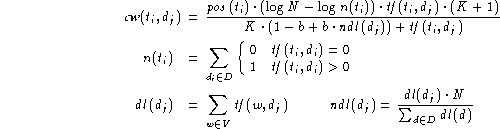| ¹ Cambridge University Engineering Department | ² Cambridge University Computer Laboratory |
| Trumpington Street, Cambridge, CB2 1PZ, UK | Pembroke Street, Cambridge, CB2 3QG, UK |
| Email: { sej28, pcw, }@eng.cam.ac.uk | { pj207, ksj }@cl.cam.ac.uk |
This paper presents work done at Cambridge University on
the
TREC-8 Spoken Document Retrieval (SDR) Track. The 500 hours
of broadcast news audio was filtered using an automatic scheme for
detecting commercials, and then transcribed using a 2-pass
HTK speech recogniser which ran at 13 times real time. The system gave
an overall word error rate of 20.5% on the 10 hour scored
subset of the corpus, the lowest in the track.
Our retrieval engine used an Okapi scheme with traditional
stopping and Porter stemming, enhanced with part-of-speech
weighting on query terms, a stemmer exceptions list,
semantic `poset' indexing, parallel collection frequency weighting,
both parallel and traditional blind relevance feedback and document
expansion using parallel blind relevance feedback.
The final system gave an Average Precision of 55.29% on
our transcriptions.
For the case where story boundaries are unknown,
a similar retrieval system, without the document expansion,
was run on a set of ``stories'' derived from windowing the
transcriptions after removal of commercials. Boundaries were forced
at ``commercial'' or ``music'' changes and some recombination
of temporally close stories was allowed after retrieval.
When scoring duplicate story hits and commercials as irrelevant, this
system gave an Average Precision of 41.47% on our transcriptions.
The paper also presents results for cross-recogniser experiments using our retrieval strategies on transcriptions from our own first pass output, AT&T, CMU, 2 NIST-run BBN baselines, LIMSI and Sheffield University, and the relationship between performance and transcription error rate is shown.
The
TREC-7 Spoken Document Retrieval (SDR)
Track showed that successful retrieval
of information where the original source of the documents is audio
is possible for small collections [4, 5].
The results showed that although retrieval performance degraded
when recogniser performance worsened, the fall off was rather
gentle and good retrieval can still be achieved on transcriptions
with over 100% Processed Term Error Rate [10],
corresponding to 66% Word Error Rate (WER) [11].
Further work has shown that various extensions to our
retrieval system can increase performance across the whole range of error
rates, with an Average Precision (AveP) of 55.88 obtained on reference
transcriptions, 55.08 on our own transcriptions (24.8% WER) and
44.15 on transcriptions from DERA [17] (61.5% WER) on
the TREC-7 task [15].
Although by speech recognition standards, the 100 hour test data
for TREC-7 represented a large task, the 2866 stories and 23 queries
provided only a small collection to test retrieval systems.
The conclusions which could be drawn about SDR were
therefore limited and a larger collection was needed to confirm
the results. The 500 hours of TREC-8 data, with 21,754 stories
and 50 queries, represents such a collection and the results presented in this
paper show how our methods adapt to a larger task.
An additional feature of our TREC-8 system is that
no knowledge about story boundaries is used for recognition,
and two retrieval runs are made for each set of transcriptions.
For the first run,
manual ``story'' boundaries have been added and commercials have been
manually removed (story-known) whilst for the second, no
such information was used and the retrieval system attempted to find
relevant passages in the document collection (story-unknown).
This led to added challenges in recognition as well as retrieval,
with a pre-processing stage being added to remove
some data automatically labelled as commercials before recognition began.
This paper firstly describes the TREC-8 SDR tasks and the data
used in both development and evaluation of our TREC-8 SDR system.
The commercial-detection scheme and the speech recogniser are described in
detail in sections 2 and
3 respectively, with the
performance of all the sites participating in the cross-recogniser
runs also given in the latter.
The retrieval engine is then described in
section 4, along with
a detailed analysis of how the individual retrieval components interacted
and affected the overall results.
Section 5
focuses on the development of the story-unknown
system using concatenated TREC-7 data and describes the
final evaluation system, giving the results for the TREC-8 task.
Cross-recogniser experiments are presented in
section 6, where
the influence of transcription quality on both the story-known
and story-unknown tasks is investigated.
Finally, conclusions are offered in
section 7.
The TREC-8 SDR track contains two main tasks.
The first, story-known (SK) SDR, is similar to the TREC-7 SDR track,
with audio from American broadcast radio and TV news programs provided
along with a list of manually-generated story (or document) boundaries.
Natural language text queries, such as
``What natural disasters occurred in the world in 1998 causing at least 10 deaths?''
are then provided and
participating sites must submit a ranked list of potentially relevant
documents after running a recognition and retrieval system on
the audio data.
Real relevance assessments generated by humans are then used
to evaluate the ranked list in terms of the standard IR
measures of precision and recall.
For TREC-8, sites may also run their retrieval system on a ``reference''
transcription which uses manually-generated closed-caption data, and on other
automatically generated transcriptions from NIST (baselines) or
from other participating sites (cross-recogniser).
The second TREC-8 task assumes no knowledge of the story boundaries
at both recognition and retrieval time (story-unknown case).
The end points of the shows are given as the start time of the
first ``story'' and end time of the last ``story'' but
no other story information, including the location of commercial
breaks within the
show, can be used. Retrieval then produces a ranked list of
shows with time stamps, which are mapped in the scoring procedure to their
corresponding story identifiers (IDs).
All but the first
occurrence of each story is marked irrelevant, as are commercials, before
the standard scoring procedure is applied.
For both tasks in TREC-8, the recognition is an on-line task, i.e. for any given audio show, only data and information derived from before the day of broadcast can be used. Therefore, unlike for TREC-7, unsupervised adaptation on the test collection can only use data up to and including the current day. Retrieval however is retrospective and can use any data up until the last day of the document collection (June 30th 1998). Further details can be found in the TREC-8 specification [6].
There are two main considerations when describing the data for SDR. Firstly the audio data used for transcription, and secondly the query/relevance set used during retrieval. Table 1 describes the main properties of the former, whilst Table 2 describes the latter, for the development (TREC-7) and evaluation (TREC-8) data sets. [Only 49 of the 50 queries for TREC-8 were adjudged to have relevant documents within the TREC-8 corpus]
To enable both the case of known and unknown story boundary SDR to be investigated, the recognition must be run on all of the 500 hours of audio without using any knowledge of the story boundaries. Since a substantial portion of the data to be transcribed was known to be commercials and thus irrelevant to broadcast news queries, an automatic method of detecting and eliminating such commercials would potentially reduce the number of false matches, thereby increasing the precision of the overall system. Removing commercials early on in processing would also reduce the amount of data that needed to be transcribed and hence speed up the overall recognition system. The first stage of our SDR system was thus a commercial detector designed to eliminate automatically some sections of audio thought to correspond to commercials, whilst retaining all the information-rich news stories.
The commercial detector was based on finding segments of repeated audio using a direct audio search (described in [12]), making the assumption that (usually) only commercials are repeated. Experiments were performed on the 8.7 hours of TREC-7 SDR data from ABC by searching for segments of similar audio within the data. The results from using 2 sliding window systems with length L and skip S to generate the initial segments are given in Table 3 along with a system which uses the automatically generated wideband segments from our 1997 Hub-4 segmenter [7]. Since the segmentation and commercial detection processes interact, results after both stages are given.
| Ts (s) | Non-story Rejection | Story Rejection |
| 0 (none) | 59.41% | 0.17% |
| 30 | 62.31% | 0.17% |
| 60 | 70.90% | 0.17% |
| 90 | 73.34% | 0.45% |
In a more realistic scenario, the user is not likely to be
interested in retrieving information which has been re-broadcast,
(i.e. repeats) whether it be a commercial or a news story.
However, the TREC-8 evaluation set-up meant it was
better to retain segments containing news content even if they
were repeats, whilst eliminating those repeated segments
which correspond to commercials.
Safeguards were therefore added to try to reduce the
probability of any matching audio which was not a commercial being
falsely rejected during the commercial detection stage.
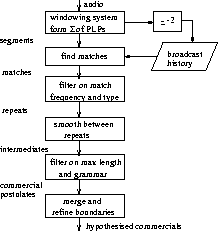
A block diagram of the commercial detection process used for the TREC-8 evaluation is given in Figure 1. Audio of the current show was analysed into 5 second windows with a window shift of 1s. Each window was characterised by the covariance matrix of the (wideband) PLP cepstral coefficients as used in the subsequent speech recognition passes. A broadcast history was built up which consisted of the windows for a certain amount of broadcast data (typically 20 hours) from that broadcaster, running up to a few days before the date of the current show. The delay was introduced to reduce the probability of an actual news story occurring in the broadcast history being directly re-broadcast in the current show. The broadcast history was initialised using the January 1998 TDT-2 data and rolled through the TREC-8 SDR evaluation data as the data was processed.
Each segment in the current show was then compared to the segments in the broadcast history. If the arithmetic harmonic sphericity distance [1] between the covariance matrices of the segments was less than a threshold, then the pair was marked as ``matching''. Note that a non-zero threshold was necessary, even when looking for identical audio, since there is no guarantee that the sampling and window shifts in each case are synchronous with the audio event in question.
For a segment to be marked as a true repeat, the number of matches between the segment and the broadcast history had to be above a given threshold, to reduce the number of false alarms due to similar, but not identical audio (for example for segments which overlapped by say 80%) matching erroneously. The probability of a re-broadcast story being labelled as a repeat was further reduced by defining the number of different days in the broadcast history which must be involved in the match before the segment was accepted as a repeat.
The merging process was then applied which relabelled as intermediates any small gaps which occurred between two segments already labelled as repeats. The intermediates were then relabelled as commercials, only if the resulting smoothed ``commercial'' was less than a critical length, the repeats always being relabelled as commercials. For the CNN shows a show ``grammar'' (constructed from the CNN TREC-7 data) was used to constrain the locations in the audio that could be labelled as commercials. Due to the limited time resolution of the commercial labelling process, conservative start and end points were also used.
The results show that automatic commercial elimination can be performed very successfully for ABC news shows. More false rejection of stories occurs with CNN data, due to the frequency of short stories, such as sports reports, occurring between commercials. The amount of commercial rejection with the VOA data is low, due mainly to the absence of any VOA broadcast history from before the test data. However, overall the scheme worked well, since 97.8% of the 42.3 hours of data removed by the COMM-EVAL system (and 95.0% of the 63.4 hours removed by the contrast COMM-2 run) were labelled as non-story in the reference.
After the commercial detection and elimination, the data is
automatically segmented and classified by bandwidth and
gender.
The segmenter initially classifies the data as either wideband (WB) speech,
narrowband (NB) speech or pure music/noise, which is discarded.
The labelling process uses Gaussian mixture models and incorporates
MLLR adaptation. A gender-dependent phone
recogniser is then run on the data and the smoothed gender change
points and silence points are used in the final segmentation.
Putative segments are clustered and successive segments in the same
cluster are merged (subject to the segment length remaining between
1 and 30 seconds). The TREC-8 segmenter, which ran in approximately
0.75x real time, included a revised mixture model for music and applied new
insertion penalties, but is essentially similar to the system
described in [7] with the modifications for faster operation
from [18].
Since silence, music and noise are discarded during segmentation, it is interesting to note the interaction between this stage and the commercial elimination phase. The results, given in Table 6, show that the proportion of data discarded by the segmenter decreases from 9.5% to 7.4% if applied after the commercial elimination stage.
| before seg. | after seg. | |
| Original | 502.4 | 454.6 |
| Commercial Elim | 460.2 | 426.0 |
The second pass used the MLLR-adapted gender-dependent triphone models
with a 108,000 word 3-gram mixture language model to generate lattices
from which a one-best output was generated using
a 4-gram model. This transcription, denoted CUHTK-s1u, was used for the
story-unknown retrieval experiments, whilst the story-known
transcription, CUHTK-s1, was simply generated by filtering this output
using the known story boundaries. The overall system gave a word error
rate of 15.7% on the November 1998 Hub4 evaluation data and 20.5%
on the 10-hour scored subset of the TREC-8 evaluation data and runs in about
13xRT on a single processor of a dual processor Pentium III 550MHz
running Linux.
The HMMs were trained using 146 hours of broadcast news audio running
up to 31st January 1998, supplied by the LDC and used for the
1998 Hub-4 task. The gender-independent wideband models were generated
initially, then narrowband models were created by single pass retraining
using a band-limited (125Hz to 3750Hz) analysis. Gender-specific models
were generated using a single training iteration to update the mean and
mixture weight parameters.
Three fixed backoff word-based language models were trained, from broadcast news text, newspaper texts and acoustic transcriptions, which were all generated using data from before 31st January 1998. The first model was built using 190 million words of broadcast news text, covering 1992-1996 (supplied by the LDC), Nov. 1996 to Jan. 1998 (from the Primary Source Media Broadcast News collection) and Jan. 1998 (from the TDT-2 corpus transcriptions). The LDC also supplied the 70m words from the Washington Post and Los Angeles Times covering 1995 to Jan. 1998, which were used for the newspaper texts model. The third model was built using 1.6m words from the 1997 and 1998 acoustic training transcriptions and 1995 Marketplace transcriptions. Single merged word based models were created which resulted in effectively interpolating the three models, forming a single resultant language model. The final 60k language model had 6.0m bigrams, 14.6m trigrams and 9.4m 4-grams, whilst the 108k model had 6.2m, 14.8m and 9.4m respectively.
As well as our own transcriptions (CUHTK-s1) we used several alternative sets to assess the effect of error rate on retrieval performance. These came from manually generated closed-captions, both unprocessed (cc-unproc) and with some standard text processing of numbers, dates, money amounts and abbreviations (cc-proc); two baselines produced by NIST using the BBN Rough'N'Ready transcription system, (NIST-B1 and NIST-B2), including a fixed and dynamically updated language model respectively; transcriptions from recognisers from LIMSI, Sheffield University, AT&T, and Carnegie Mellon University (CMU); and the output of the first pass of our system (CUHTK-p1).
A 10-hour subset of the TREC-8 (story-known) evaluation data was taken and detailed transcriptions made by the LDC for scoring the recognisers. The results are given in Table 7.
The basic system we used for SK retrieval in TREC-8 is similar to that presented at TREC-7 [11], but the final system also contains several new devices. These include Semantic Poset Indexing (SPI) and Blind Relevance Feedback for query expansion, both on the test collection itself (BRF) and a parallel corpus (PBRF), all of which have been shown to increase performance on the TREC-7 task [14, 15]. A new technique called Parallel Collection Frequency Weighting (PCFW) is also presented along with an implementation of document expansion using the parallel corpus within the framework of the Probabilistic Model.
A term ti
is a set of words or word sequences from queries or
documents which are considered to be a unique semantic unit.
We call the first set of operations which define the relationship between
terms and their components preprocessing.
The following preprocessing techniques are sequentially applied on all
transcriptions and queries before indexing and retrieval.
The words are first made lower case and some punctuation characters are removed. Hyphens and digital numbers were kept even though they do not occur in the ASR-transcribed documents. [One might think that some hyphens should be removed from the manually transcribed documents (e.g. health-related) whereas others should not (e.g. anti-abortion). Because of a lack of preliminary experiments we decided not to remove any hyphens or digits.]
Some sequences of words are then mapped to create single compound words.
and some single-word mappings are also applied to deal with
known stemming exceptions and alternative (possibly incorrect) spellings
in the manual transcriptions. The list of compound words and mappings was
created manually for our TREC-7 SDR system [11].
A set of non-content (stop) words was removed from all documents and queries,
with an additional set also being removed from just the queries,
e.g. {find,documents,..}.
Abbreviations, (in several forms) are mapped into single words, e.g.
[C. N. N. -> cnn].
The use of Porter's well-established stemming
algorithm [19] allows
several forms of a word to be considered as a unique term, e.g.
ti(train)
= {train, training, trainer, trains, ...}.
Unlike the mapping techniques, this algorithm is not limited by the use of a
fixed thesaurus and therefore every new word in a test
collection can be associated with its various forms.
The index (inverted) file contains all the information about a given collection of documents that is needed to compute the document-query scores. For the collection, each term ti in the term-vocabulary has an associated:
Semantic Poset Indexing (SPI) [14] is used to allow tf(t i ,d) and n(t i ) to take into account some semantic relationships between terms. More specifically, semantic poset structures based on unambiguous noun hyponyms from WordNet [2] and a manually-built geographic locations tree were made. A term occurring in a poset is then redefined as the union of itself and all more specific terms in the poset associated with that term, before the statistics are calculated. For example, the term frequency for a term ti thus becomes the sum of the frequencies of occurrence of itself and all more specific related terms within a given document.
A part-of-speech (POS) tagger is run over the queries and the weight of each query term ti is scaled by a factor pos(t i ) using the POS weighting scheme from our TREC-7 system [11]. The score for a document with respect to a given query is then obtained by summing the combined weights, cw(t i ,d j ) , for each query term ti according to the following formulae:
where V is the term vocabulary for the whole document collection D; and K and b are tuning constants
When the documents in the collection are ranked according to a given query, it is possible to expand the query by adding several terms which occur frequently within the top documents but rarely within the whole collection. The T terms which obtain the highest Offer Weight are added to the query. The Offer Weight of a term ti is :
![]()
where R is the number of top documents which are assumed to be relevant;
r the number of assumed relevant documents in which at least one
component of
ti occurs;
n the total number of documents in which at least one
component of
ti occurs;
and N is the total number of documents in the
collection.
The method of document expansion described within the Vector Model in [20] at TREC-7, can also be used within the probabilistic framework. By considering a document as a pseudo-query, it is possible to expand that document using BRF on a parallel collection. For a given document, the 100 terms with the lowest n(t i ) are used as the pseudo-query. BRF is then applied on the parallel collection (with R=10) and the top 400 terms are added to the original document with a term frequency based on their Offer Weight.
If the test collection is small or contains many transcription errors, the values of n(t i ) may not be sufficiently reliable to use in the prediction of relevance. It is possible to exploit the larger, higher quality parallel collection to obtain better estimates for n(t i ) (and N), to use within the combined weights formula. The collection number, n(t i ) , for a given term is therefore replaced by the sum of the collection number for that term on the test corpus and the parallel corpus; with the number of documents, N, being adjusted accordingly.
The index file was made as follows:
The query file was produced by:
The parallel collection used in DPBRF, PBRF and PCFW is composed of 51,715 stories extracted from the L.A. Times, Washington Post and New York Times over the period of Jan 1st to June 30th 1998. This contains the TREC-8 SDR test collection period (Feb 1st to June 30th 1998).
The AveP results for our final system on all the sets of transcriptions made available is given in Table 13 in section 6. Here we concentrate on the effect on performance of each aspect of the system on our own CUHTK-s1 transcriptions.
It is important to try to understand the contribution of each
individual device towards the overall performance of the IR system.
Table 8 gives the values of AveP we obtain
by progressively decomposing the system.
Lines 1 and 2 show that the addition of all these devices together
led to a relative increase in AveP of 23% .
Lines 3-5 show that adding just PBRF or BRF individually
improve the performance over a system with no blind relevance
feedback, but applying PBRF alone gives better results than their combination.
Lines 6-11 show that the improvement due to PCFW is
reduced by the use of PBRF. BRF degrades the performance even more
when PCFW is present.
A similar behaviour can be observed on lines 12-15 for POSW, namely
that adding POSW increases performance on the basic system, but degrades
when all the other devices are also included.
However, this is not the case for DPBRF, as lines 16-17 show that
including DPBRF when all other devices are present increases
AveP by 5.7% relative.
SPI exhibits a rather different behaviour. It has no significant effect on
the baseline system (see lines 18-19), but since the
parallel corpus was indexed with SPI, all the devices apart from POSW
were affected by the use of this technique.
Lines 20 and 21 show that AveP reached 56.72% when SPI was not
used and thus SPI actually degraded the performance by 2.5% relative.
By comparing lines 20 and 22, we can see that the poor contribution
of BRF was due to the inclusion of SPI.
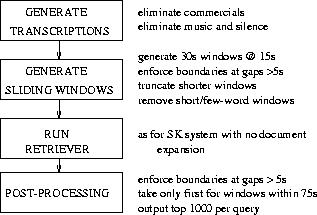
For the SU evaluation, no knowledge of the manually-labelled story boundaries can be used either in retrieval or recognition. The system must present a ranked list of show:time stamps, which are mapped to the corresponding story (or commercial) IDs before retrieval performance evaluation, with commercials and duplicates scored as irrelevant.
Two main approaches to the SU task
exist, the first consists of labelling story
boundaries automatically and then running the standard retrieval engine;
whilst the second never explicitly finds the story boundaries, but rather
locates the relevant passages in the transcriptions and performs some
merging of temporally close relevant passages to reduce the possibility
of producing multiple hits from the same story source. We investigated one
technique from each approach, namely Hearst's text-tiling [8] for
topic boundary detection and a windowing/ recombination system.
For development, the 100 hours of TREC-7 SDR test data was used.
This did not exactly model the TREC-8 SU task, since
the commercials had already manually been removed from the data, but
offered a reasonable basis to compare the different systems.
Two methods of scoring were used, the first is the official evaluation
scoring procedure, where all instances of a story other than the
first one are scored as irrelevant (named dup-irrel).
The second, by removing all
duplicates before scoring, was more lenient and provided an indication
of the ``best'' performance that could be achieved if a perfect
merging system (that removed duplicates, but did not re-score or re-order
the ranked list) were added after retrieval. This was named
dup-del and represents a reasonable
indication of the potential of any given system.
A simple experiment was conducted to compare a text-tiling system
with a windowing system. Text-tiling was originally designed to
group paragraphs in long textual reports together and therefore
is not ideally suited to the SU-SDR task, since the transcriptions
contain no case, sentence or paragraph information.
``Pseudo'' paragraphs of 10s of speech were made for each show and the
default text-tiling parameters [8] were used along with some additional
abbreviations
processing, to obtain the ``tile''
boundaries. Our standard retriever,
similar to our TREC-7 system [11], was then used to produce
the final ranked list.
The windowing system made pseudo-stories of a given length and skip
before running the retriever as before.
The results are given in Table 9.
The windowing system seemed to offer greatest potential and hence the
basis of the SU system was chosen to be a sliding window of length
30 seconds and skip 15 seconds.
| System | dup-irrel | dup-del |
| Baseline from Table 9 | 33.9 | 46.1 |
| Improved Retriever | 36.5 | 51.2 |
| Improved Retriever + forced-breaks | 36.0 | 51.6 |
| Tmerge | 0 | 15 | 30 | 45 | 60 | 75 | 90 | 105 | 120 |
| dup-irrel | 36.0 | 45.0 | 45.6 | 46.2 | 46.9 | 47.5 | 47.8 | 48.1 | 48.0 |
| dup-del | 51.6 | 51.6 | 51.1 | 50.7 | 50.6 | 50.6 | 50.3 | 50.3 | 50.0 |
Attempts were made to modify the score from the retriever of any window which represented a merged group of windows, before re-ordering during the post-processing phase, but this proved not to be beneficial for the TREC-7 data. Finally hard breaks, as defined by a certain length gap in the audio, were also enforced in the post-processing phase, so that no merging could take place over such a break. The results are given in Table 12 for a Tmerge of 75 seconds and 120s.
|
Audio Gap for Boundary |
Tmerge =75s | Tmerge =120s | ||
| dup-irrel | dup-del | dup-irrel | dup-del | |
| 100s or
|
47.51 | 50.62 | 48.03 | 50.03 |
| 15s | 47.46 | 50.61 | 48.05 | 50.11 |
| 10s | 47.49 | 50.63 | 48.08 | 50.13 |
| 5s | 47.46 | 50.64 | 48.34 | 50.45 |
The final system, summarised in Figure 2, gave an AveP of 41.47 (R-prec=41.98) on our own transcriptions on the TREC-8 task. A more detailed analysis of the SU results for TREC-8 can be found in [13].
Several sets of transcriptions from other participating sites were offered to allow comparisons to be made between retrieval using different recognition systems. The detailed breakdown of the word error rate of these transcriptions is given in Table 7 in section 3.1. The AveP for both the SK and SU runs, along with the term error rate [10] after stopping and stemming (SSTER) and word error rate (WER) is given in Table 13. The AveP for a benchmark system with no relevance feedback, document expansion or parallel collection frequency weights (BASE) is given as a comparison. [The unprocessed version of the closed caption transcriptions cc-unproc is not included in all the subsequent analysis since it does not reflect the standard output format.]
The term error rate after document expansion (DETER) is also given in Table 13 as a comparison. To calculate this measure, pre-processing, poset mapping and then document expansion are performed on both the reference and hypothesis transcriptions before the standard term error rate is calculated. [Since there is no guarantee that the terms added to the reference transcriptions during document expansion will be ``good'' terms for the subsequent retrieval runs, the new ``reference'' transcriptions may no longer represent the ideal case, but it was hoped that this measure would allow the effects of document expansion to be seen and in particular to show up any major problems which occurred during the document expansion process.]
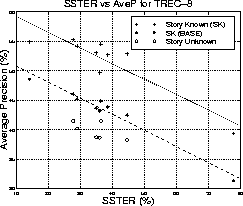
Figure 3 shows the relationship between stopped-stemmed term error rates (SSTER) and AveP. Whilst the benchmark (BASE) performance can be predicted reasonably well from SSTER, there is more, seemingly unpredictable, variation for the case of the complete SK system. In particular, the AveP for the NIST-B1 and cc-unproc runs is much worse than that predicted by the SSTER. However, the DETER for both these cases is unusually high, suggesting the problem for these runs lay in the document expansion process. [It was found that a disk filling up during the document expansion process for NIST-B1 was responsible for the relatively poor performance for this case. When rectified, the AveP for NIST-B1 was 52.81]
It is interesting to note that the best-fit lines for both the complete SK
system and the benchmark SK cases are almost parallel,
( gradients -0.26 and -0.27 respectively),
showing that the inclusion of relevance feedback for
query and document expansion and parallel collection frequency weights
improves the overall AveP by around 8.5% absolute across
the complete range of transcription error rates.
The SU results follow a roughly similar pattern, suggesting that generally transcriptions which work well for the SK case also work well for the SU case. It is pleasing to note that the output from the first pass of our system, CUHTK-p1, does better than might be predicted from its error rate. This is due in part to the reduction in false alarms because of the elimination of commercials in the system. This is confirmed by the results given in Table 14, which show that the AveP on CUHTK-p1 transcriptions would have fallen by 0.5% if the commercial detector had not been used, whereas the performance on LIMSIs transcriptions increases by over 0.5% when the detected commercials are filtered out during the post-processing stage (see [13] for more details).
| Run | No Commercials removed | COMM-EVAL removed |
| CUHTK-p1 | 41.00% | 41.50% |
| LIMSI | 40.19% | 40.75% |
Term Error Rates were introduced in [11]
to model the input to the retriever
more accurately than the traditional word error rate.
If knowledge about the retrieval process itself is known in advance,
then the TER can be modified to exploit this information to model
the retrieval process more closely and therefore hopefully provide
a better predictor of the performance of the final system.
An example of this is using SSTER, where the stopping, mapping and
stemming processes used in the first stage of indexing the transcriptions,
is incorporated into the error rate calculation.
If more information is known about how the scores are
generated within the retriever for a given term, then
new TERs can be defined which incorporate this information.
The generic TER function thus becomes:
![]()
where fw is some function which generally depends on the word w, R is the reference and H the hypothesis. This can be seen to reduce to the standard TER when f is the identity function. Some other possibilities for the function fw which allow the collection frequency weighting (inverse document frequency), [Another method of modifying the TER to model retrieval weighting more closely can be found in [20]]
or the combined weights formula to be included directly are:
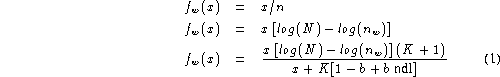
where N, K, b, n and ndl have the same meaning as in
section 4.1.3.
It is also possible to include the frequency of each term
in the query as a scale factor within
fw if the queries
are known, but this makes the score query-dependent, which may be
undesirable, and care must be taken in defining the query terms
if relevance feedback is used for query expansion.
The TERs using (1), including stopping, stemming, mapping, posets,
document expansion and parallel collection frequency
weights within the
combined weighting formula are given in Table 15.
Unfortunately these numbers do not appear to offer a better predictor
for our AveP results. This may be because
the words added to the ``reference'' during document expansion may not
be the best in terms of retrieval performance, or that only the query terms
themselves should be taken into account, or simply the overall performance
on the entire 500 hour collection cannot be predicted well using the
scored 10 hour subset.
| Rec. | HTK | cc-proc | HTK-p1 | LIMSI | NIST-B2 | Sheff | AT&T | cc-unproc | NIST-B1 | CMU |
| Error | 55.51 | 37.93 | 67.86 | 57.20 | 62.46 | 72.80 | 66.79 | 104.75 | 91.90 | 121.68 |
This paper has described the systems developed at Cambridge
University for the 1999 TREC-8 SDR story known and story unknown
evaluations.
A new method of automatically detecting commercials has been shown
to work well, with 97.8% of the 42.3 hours of data automatically
labelled as commercials being marked as non-story information by
humans. By automatically eliminating these ``commercials'' at
an early stage, the computational effort required during
speech recognition was reduced by
8.4% and the Average Precision for the story unknown task was
increased by 1.2% relative.
Two HTK-based transcription systems were made. The first
ran in 3 times real time and gave a word error rate (WER) of 26.6% on the
scored 10 hour subset of the data. The second ran at 13 times
real time and included a second pass with a 108k vocabulary and
speaker adaptation, giving a WER of 20.5%, the lowest in the track by
a statistically significant margin.
Several extensions to our retriever have been described and shown to
increase Average Precision on our best transcriptions for the story-known
case by 23% relative, giving a final value of 55.29%.
These included semantic poset indexing, blind relevance
feedback, parallel blind relevance feedback for both query
and document expansion
and parallel collection frequency weighting.
The system developed for the case where story boundaries
were not known included automatic detection and elimination of commercials,
windowing using the segmentation information, retrieval using
all the strategies developed for the story-known case except document
expansion, and post-filtering to recombine multiple hits from the
same story.
The final system gave an average precision of 41.5% on both
sets of our transcriptions.
Finally, experiments were described using other transcriptions and the relationship between transcription error rate and performance was investigated. The results from TREC-7 showing that the degradation of performance with increasing error rate was fairly gentle were confirmed on this significantly larger data set.
This work is in part funded by an EPSRC grant reference
GR/L49611.
Thanks to Tony Robinson for the initial idea that repetitions
of audio could help to indicate the presence of commercials.