Project Description
Model-based noise robustness schemes have been shown to yield
excellent performance for automatic speech recognition (ASR) systems,
even in low signal-to-noise-ratio (SNR) conditions. These approaches
estimate models of the background noise, including both additive and
convolutional distortions, and use these to alter the acoustic model
parameters to reflect those present in the target environment. These
approaches can also be used within an adaptive training environment
allowing noise corrupted data to be used efficiently during training
to obtain a neutral, canonical, speech model which is suited for
adaptation to a range of target environments. This work will initially
apply and investigate state-of-the-art model-based compensation
approaches developed for ASR systems to keyword spotting in the RATS
target domain where SNRs of less than 10dB are specified. This will
include improving existing work on discriminative adaptive training
approaches based on schemes such as Vector Taylor Series compensation
(VTS), Joint Uncertainty Decoding (JUD) and Predictive CMLLR
(PCMLLR). In addition, novel forms of model-based compensation
specifically aimed at addressing the low SNR environments within the
RATS domain will be developed.
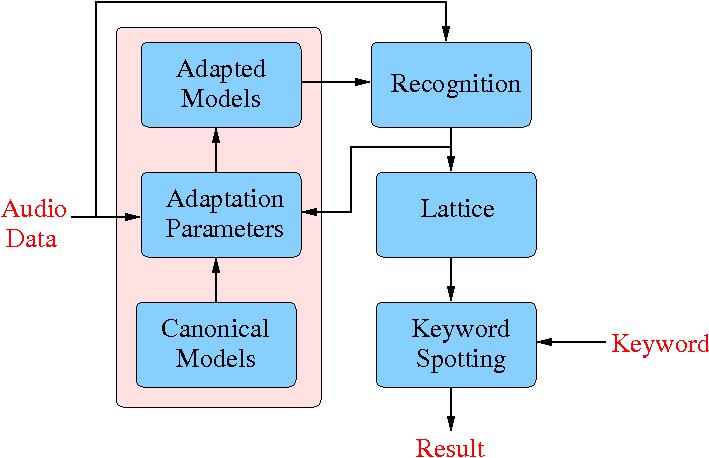
One problem with model-based approaches is that they require a
representation of how the background noise conditions affect the
speech. Approximations in this "mismatch" function can impact
performance. Furthermore, though model-based compensation schemes are
able to handle background acoustic environments, to achieve the levels
of keyword spotting performance required under the RATS programme it
will be necessary to adapt, in a fully automated and unsupervised
fashion, the acoustic models to be representative of the specific
speaker for that utterance. Schemes for combining model-based
compensation approaches with speaker adaptation approaches, such as
MLLR and CMLLR, will be examined. For these speaker adaptation
schemes there is no mismatch function with its associated
approximations, general transformations of the acoustic models are
estimated. These transformations require more data to obtain robust
estimates, and depending on the amount of available data may not
handle the non-linearities associated with the impact of background
noise conditions. Thus appropriate schemes for combining speaker
adaptation approaches with model compensation schemes should yield
significant gains. Another challenge is to refine existing speaker
adaptation approaches to operate well in low SNR environments. This
will build on existing work such as Noisy CMLLR (NCMLLR) adaptation
which combines attributes of both model compensation schemes and
speaker adaptation. For these low SNR conditions it may be useful to
examine discriminative approaches to estimating the transforms. As any
hypotheses used to estimate the transform are liable to be error-full,
schemes based on discriminative mapping functions will be examined.
Personnel Associated with the Project
Past members
top
RATS Patrol  Consortium Partners
Consortium Partners
top
![[Dept of Engineering]](http://www.eng.cam.ac.uk/images/house_style/engban-s.gif)