Project Description
The aim of this project is to significantly improve the performance of
automatic speech recognition systems across a wide range of
environments, speakers and speaking styles. The performance of
state-of-the-art speech recognition systems is often acceptable under
fairly controlled conditions and where the levels of background noise
are low. However for many realistic situations there can be high
levels of background noise, for example in-car navigation, or widely
ranging channel conditions and speaking styles, such as observed on
YouTube-style data. This fragility of speech recognition systems is
one of the primary reasons that speech recognition systems are not
more widely deployed and used. It limits the possible domains in which
speech can be reliably used, and increases the cost of developing
applications as systems must be tuned to limit the impact of this
fragility. This includes collecting domain specific data and
significant tuning of the application itself.
The vast majority of research for speech recognition has concentrated
on improving the performance of hidden Markov model (HMM) based
systems. HMMs are an example of a generative model and are currently
used in state-of-the-art speech recognition systems. A wide number of
approaches have been developed to improve the performance of these
systems under speaker and noise changes. Despite these approaches,
systems are not sufficiently robust to allow speech recognition
systems to achieve the level of impact that the naturalness of the
interface should allow.
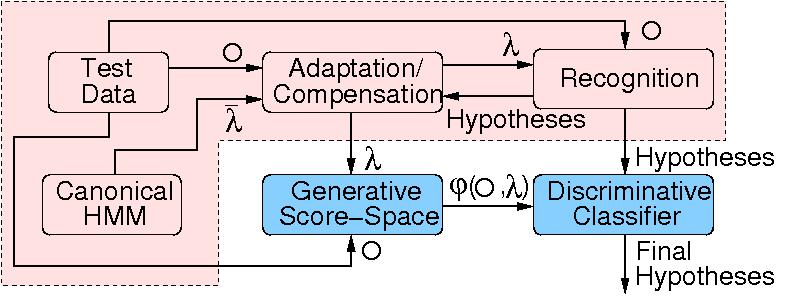
This project will combine the current generative models developed in
the speech community with discriminative classifiers used in both the
speech and machine learning communities. An important, novel, aspect
of the proposed approach is that the generative models are used to
define a score-space that can be used as features by the
discriminative classifiers. This approach has a number of
advantages. It is possible to use current state-of-the-art adaptation
and robustness approaches to compensate the acoustic models for
particular speakers and noise conditions. As well as enabling any
advances in these approaches to be incorporated into the scheme, it is
not necessary to develop approaches that adapt the discriminative
classifiers to speakers, style and noise. One of the major problems
with speech recognition is that variable length data sequences must be
classified. Using generative models also allows the dynamic aspects of
speech data to be handled without having to alter the discriminative
classifier. The final advantage is the nature of the score-space
obtained from the generative model. Generative models such as HMMs
have underlying conditional independence assumptions that, whilst
enabling them to efficiently represent data sequences, do not
accurately represent the dependencies in data sequences such as
speech. The score-space associated with a generative model does not
have the same conditional independence assumptions as the original
generative model. This allows more accurate modelling of the
dependencies in the speech data.
The combination of generative and discriminative classifiers will be
investigated on two very difficult forms of data that current systems
perform badly on. The first task is adverse environment recognition of
speech. In these situations there are very high levels of background
noise which causes severe degradation in system performance. Data of
interest for this task will be specified in collaboration with Toshiba
Research Europe Ltd. The second task of interest is large vocabulary
speech recognition of data from a wide-range of speaking styles and
conditions. Google has supplied transcribed data from YouTube to allow
evaluation of systems on highly diverse data. The project will yield
significant performance gains over current state-of-the-art approaches
for both tasks.
![[Dept of Engineering]](http://www.eng.cam.ac.uk/images/house_style/engban-s.gif)